基础介绍-基于v1.12
Go语言特点:
- Go 语言容易上手;
- Go 语言解决了并发编程和写底层应用开发效率的痛点;
- Go 语言有 Google 这个世界一流的技术公司在后面;
- Go 语言的杀手级应用是 Docker,而 Docker 的生态圈在这几年完全爆棚了。
所以,Go 语言的未来是不可限量的。Go 可能会吞食很多 C、C++、Java 的项目。不过,Go 语言所吞食主要的项目应该是中间层的项目,既不是非常底层也不会是业务层。
也就是说,Go 语言不会吞食底层到 C 和 C++ 那个级别的,也不会吞食到高层如 Java 业务层的项目。Go 语言能吞食的一定是 PaaS 上的项目,比如一些消息缓存中间件、服务发现、服务代理、控制系统、Agent、日志收集等等,没有复杂的业务场景,也到不了特别底层(如操作系统)的中间平台层的软件项目或工具。而 C 和 C++ 会被打到更底层,Java 会被打到更上层的业务层。
Golang的官方网站:https://golang.org/
Golang的国内网站:https://golang.google.cn/
环境安装
先配置GOROOT,就是go的安装目录
然后配置GOPATH
Gopath就是Go项目代码存放的位置。这个是我们自己定义的目录。就好比是其他IDE的Workspace。
该目录下有3个子目录:src,pkg,bin
GO代码必须在工作空间内。工作空间是一个目录,其中包含三个子目录:
src —- 里面每一个子目录,就是一个包。包内是Go的源码文件
pkg —- 编译后生成的,包的目标文件
bin —- 生成的可执行文件。
配置环境变量:
- GOROOT:Go安装路径(例:C:\Go)
- GOPATH:Go工程的路径(例:E:\go)。如果有多个,就以分号分隔添加
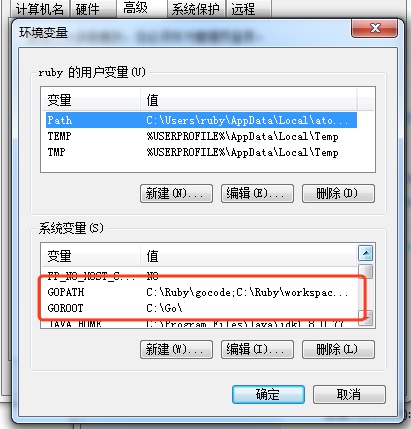
Path:在path中增加:C:\Go\bin;%GOPATH%\bin;
需要把GOPATH中的可执行目录也配置到环境变量中, 否则你自行下载的第三方go工具就无法使用了
go env:查看配置信息
go version:版本信息
- 工作目录就是我们用来存放开发的源代码的地方,对应的也是Go里的GOPATH这个环境变量。这个环境变量指定之后,我们编译源代码等生成的文件都会放到这个目录下,GOPATH环境变量的配置参考上面的安装Go,配置到Windows下的系统变量里。
- GOPATH之下主要包含三个目录: bin、pkg、src。bin目录主要存放可执行文件; pkg目录存放编译好的库文件, 主要是*.a文件; src目录下主要存放go的源文件
Day01-8 hello world
gopath目录
gopath目录就是我们存储我们所编写源代码的目录。该目录下往往要有3个子目录:src,bin,pkg。
src —- 里面每一个子目录,就是一个包。包内是Go的源码文件
pkg —- 编译后生成的,包的目标文件
bin —- 生成的可执行文件。
1.2 编写第一个程序
1.在HOME/go的目录下,(就是GOPATH目录里),创建一个目录叫src,然后再该目录下创建一个文件夹叫hello,在该目录下创建一个文件叫helloworld.go,并双击打开,输入以下内容:
1 | package main |
2.执行go程序
执行go程序由几种方式
方式一:使用go run命令:移动到文件目录中,直接运行源文件:go run helloworld.go
方式二:使用go install 命令
step1:打开终端:在任意文件路径下,运行:
go install hello (hello为包名)
也可以进入项目(应用包)的路径,然后运行:
go install
注意,在编译生成go程序的时,go实际上会去两个地方找程序包:
GOROOT下的src文件夹下,以及GOPATH下的src文件夹下。
在程序包里,自动找main包的main函数作为程序入口,然后进行编译。
step2:运行go程序
在/home/go/bin/下(如果之前没有bin目录则会自动创建),会发现出现了一个hello的可执行文件,用如下命令运行:
./hello
方式三:使用go build命令
任意位置go build hello ,或者项目文件夹内go build,都能编译程序。在哪里运行命令,就在哪里生成二进制程序。
1.3 第一个程序的解释说明
3.2.1 package
- 在同一个包下面的文件属于同一个工程文件,不用
import包,可以直接使用 - 在同一个包下面的所有文件的package名,都是一样的
- 在同一个包下面的文件
package名都建议设为是该目录名,但也可以不是
3.2.2 import
import “fmt” 告诉 Go 编译器这个程序需要使用 fmt 包的函数,fmt 包实现了格式化 IO(输入/输出)的函数
可以是相对路径也可以是绝对路径,推荐使用绝对路径(起始于工程根目录)
点操作
我们有时候会看到如下的方式导入包1
2
3import(
. "fmt"
)这个点操作的含义就是这个包导入之后在你调用这个包的函数时,你可以省略前缀的包名,也就是前面你调
用的
fmt.Println("hello world")可以省略的写成Println("hello world")别名操作
别名操作顾名思义我们可以把包命名成另一个我们用起来容易记忆的名字1
2
3import(
f "fmt"
)别名操作的话调用包函数时前缀变成了我们的前缀,即
f.Println("hello world")_操作
这个操作经常是让很多人费解的一个操作符,请看下面这个import1
2
3
4import (
"database/sql"
_ "github.com/ziutek/mymysql/godrv"
)_操作其实是引入该包,而不直接使用包里面的函数,而是调用了该包里面的init函数
3.3.3 main
main(),是程序运行的入口。
1.4 包的说明
我们知道源代码都是存放在GOPATH的src目录下,那么多个多个项目的时候,怎么区分呢?答案是通过包,使用包来组织我们的项目目录结构。有过java开发的都知道,使用包进行组织代码,包以网站域名开头就不会有重复,我自己的go项目都放在这个文件夹里,这样就不会和其他人的项目冲突,包名也是唯一的。
如果有自己的域名,那也可以使用自己的域名。如果没有个人域名,现在流行的做法是使用你个人的github名,因为每个人的是唯一的,所以也不会有重复。
如上,src目录下跟着一个个域名命名的文件夹。再以github.com文件夹为例,它里面又是以github用户名命名的文件夹,用于存储属于这个github用户编写的go源代码。
Day01-9.Go的执行原理以及Go的命令
一、Go的源码文件
Go 的源码文件分类,分为三类:
1、命令源码文件:
声明自己属于 main 代码包、包含无参数声明和结果声明的 main 函数。
命令源码文件被安装以后,GOPATH 如果只有一个工作区,那么相应的可执行文件会被存放当前工作区的 bin 文件夹下;如果有多个工作区,就会安装到 GOBIN 指向的目录下。
命令源码文件是 Go 程序的入口。
同一个代码包中最好也不要放多个命令源码文件。多个命令源码文件虽然可以分开单独 go run 运行起来,但是无法通过 go build 和 go install。
我们先打开上次课的hello目录,然后复制helloworld.go为helloworld2.go文件,并修改里面的内容:
1 | package main |
hello目录下有两个go文件了,一个是helloworld.go,一个是helloworld2.go。先说明一下,在上述文件夹中放了两个命令源码文件,同时都声明自己属于 main 代码包。
打开终端,进入hello这个目录,也可以看到这两个文件:
1 | localhost:~ ruby cd go/src/hello |
然后我们分别执行go run命令,可以看到两个go文件都可以被执行:
1 | localhost:hello ruby$ go run helloworld.go |
接下来执行 go build 和 go install ,看看会发生什么:
1 | localhost:hello ruby$ go build |
这也就证明了多个命令源码文件虽然可以分开单独 go run 运行起来,但是无法通过 go build 和 go install。
同理,如果命令源码文件和库源码文件也会出现这样的问题,库源码文件不能通过 go build 和 go install 这种常规的方法编译和安装。具体例子和上述类似,这里就不再贴代码了。
所以命令源码文件应该是被单独放在一个代码包中。
2、库源码文件
库源码文件就是不具备命令源码文件上述两个特征的源码文件。存在于某个代码包中的普通的源码文件。
库源码文件被安装后,相应的归档文件(.a 文件)会被存放到当前工作区的 pkg 的平台相关目录下。
3、测试源码文件
名称以 _test.go 为后缀的代码文件,并且必须包含 Test 或者 Benchmark 名称前缀的函数:
1 | func TestXXX( t *testing.T) { |
名称以 Test 为名称前缀的函数,只能接受 *testing.T 的参数,这种测试函数是功能测试函数。
1 | func BenchmarkXXX( b *testing.B) { |
名称以 Benchmark 为名称前缀的函数,只能接受 *testing.B 的参数,这种测试函数是性能测试函数。
现在答案就很明显了:
命令源码文件是可以单独运行的。可以使用 go run 命令直接运行,也可以通过 go build 或 go install 命令得到相应的可执行文件。所以命令源码文件是可以在机器的任何目录下运行的。
举个栗子:
比如平时我们在 LeetCode 上刷算法题,这时候写的就是一个程序,这就是命令源码文件,可以在电脑的任意一个文件夹新建一个 go 文件就可以开始刷题了,写完就可以运行,对比执行结果,答案对了就可以提交代码。
但是公司项目里面的代码就不能这样了,只能存放在 GOPATH 目录下。因为公司项目不可能只有命令源码文件的,肯定是包含库源码文件,甚至包含测试源码文件的。
二、Go的命令
目前Go的最新版1.12里面基本命令有以下17个。
我们可以打开终端输入:go help即可看到Go的这些命令以及简介。
1 | bug start a bug report |
其中和编译相关的有build、get、install、run这4个。接下来就依次看看这四个的作用。
在详细分析这4个命令之前,先罗列一下通用的命令标记,以下这些命令都可适用的:
| 名称 | 说明 |
|---|---|
| -a | 用于强制重新编译所有涉及的 Go 语言代码包(包括 Go 语言标准库中的代码包),即使它们已经是最新的了。该标记可以让我们有机会通过改动底层的代码包做一些实验。 |
| -n | 使命令仅打印其执行过程中用到的所有命令,而不去真正执行它们。如果不只想查看或者验证命令的执行过程,而不想改变任何东西,使用它正好合适。 |
| -race | 用于检测并报告指定 Go 语言程序中存在的数据竞争问题。当用 Go 语言编写并发程序的时候,这是很重要的检测手段之一。 |
| -v | 用于打印命令执行过程中涉及的代码包。这一定包括我们指定的目标代码包,并且有时还会包括该代码包直接或间接依赖的那些代码包。这会让你知道哪些代码包被执行过了。 |
| -work | 用于打印命令执行时生成和使用的临时工作目录的名字,且命令执行完成后不删除它。这个目录下的文件可能会对你有用,也可以从侧面了解命令的执行过程。如果不添加此标记,那么临时工作目录会在命令执行完毕前删除。 |
| -x | 使命令打印其执行过程中用到的所有命令,并同时执行它们。 |
1. go run
专门用来运行命令源码文件的命令,注意,这个命令不是用来运行所有 Go 的源码文件的!
go run 命令只能接受一个命令源码文件以及若干个库源码文件(必须同属于 main 包)作为文件参数,且不能接受测试源码文件。它在执行时会检查源码文件的类型。如果参数中有多个或者没有命令源码文件,那么 go run 命令就只会打印错误提示信息并退出,而不会继续执行。
这个命令具体干了些什么事情呢?来分析分析,我们先重新创建一个新文件:mytest.go,并加入以下代码:
1 | package main |
执行go run 配合-n:
1 | localhost:hello ruby$ go run -n mytest.go |
运行效果图:
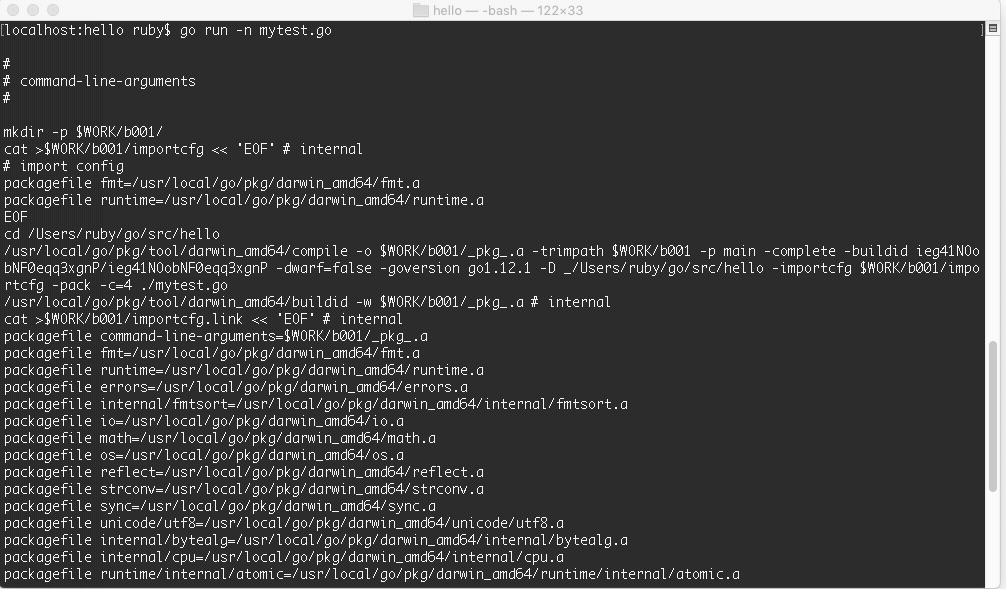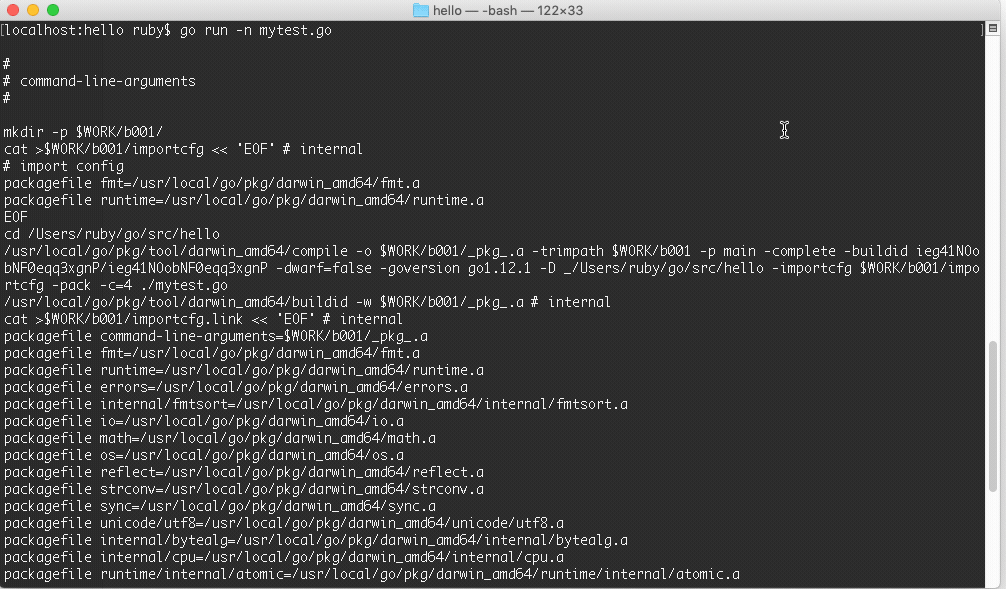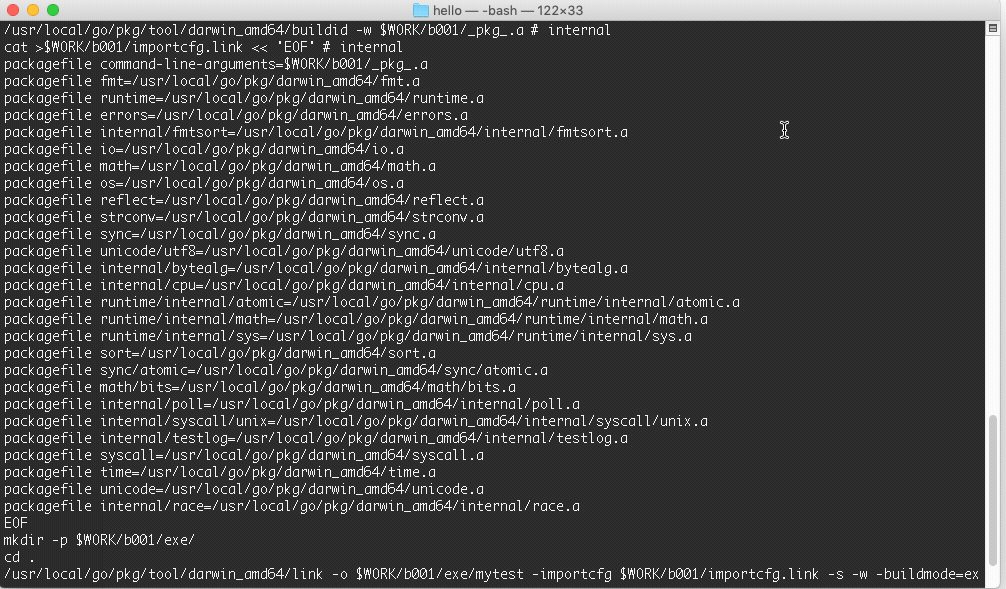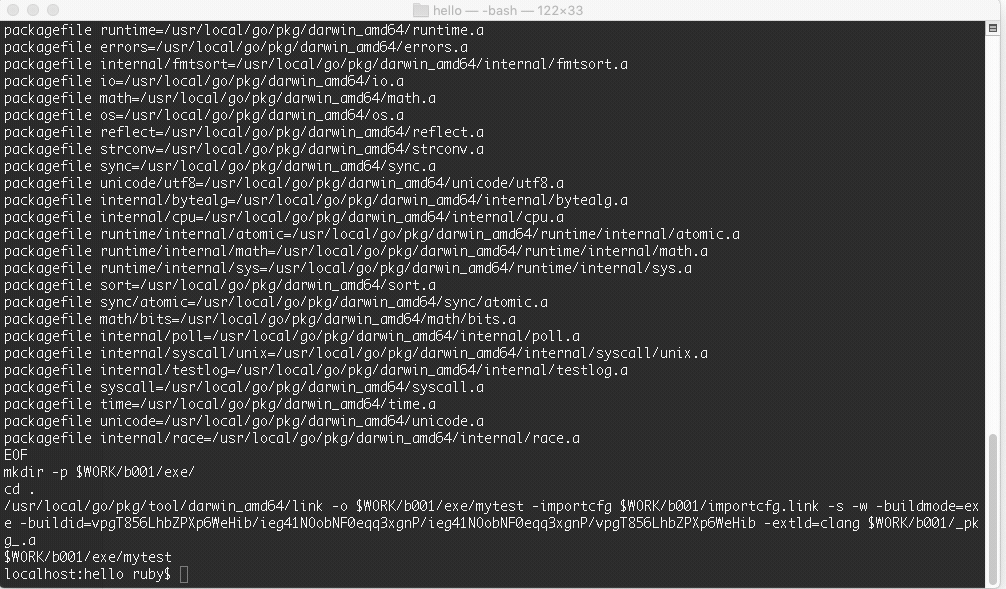
这里可以看到创建了两个临时文件夹 b001 和 exe,先执行了 compile 命令,然后 link,生成了归档文件.a 和 最终可执行文件,最终的可执行文件放在 exe 文件夹里面。命令的最后一步就是执行了可执行文件。
总结一下如下图:
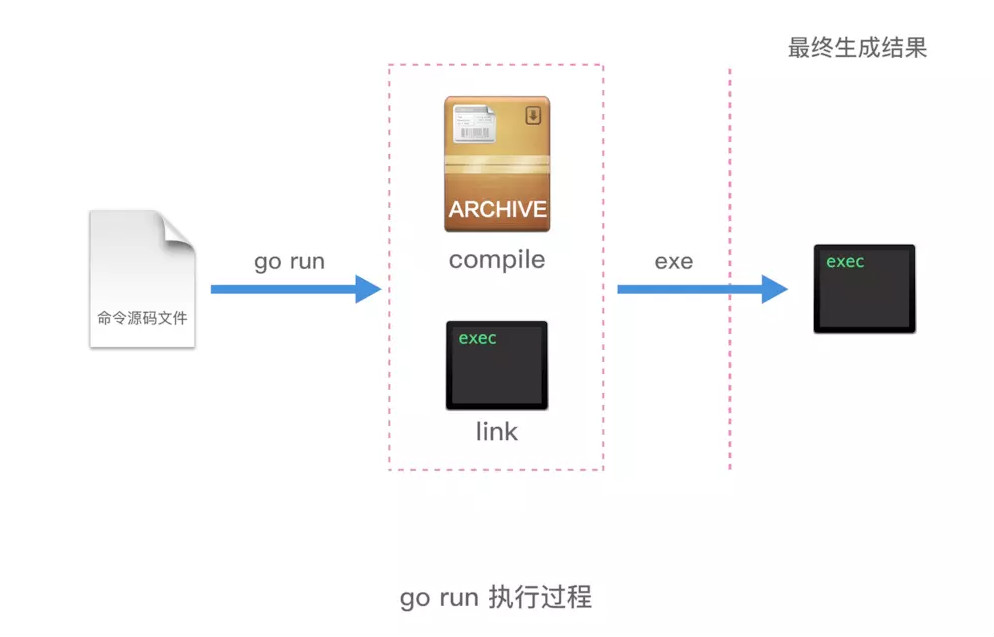
举个例子,生成的临时文件可以用 go run -work看到,比如当前生成的临时文件夹是如下的路径:
1 | localhost:hello ruby$ go run -work mytest.go |
我们进入:/var/folders/kt/nlhsnpgn6lgd_q16f8j83sbh0000gn/T/go-build593750496目录,可以看到如下目录结构:
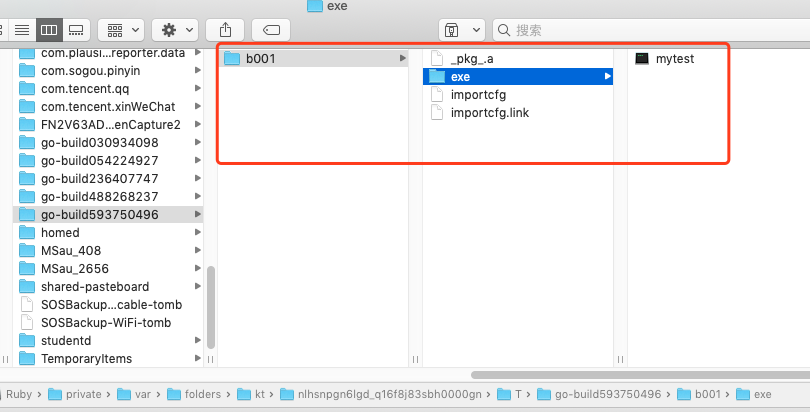
可以看到,最终 go run命令是生成了2个文件,一个是归档文件,一个是可执行文件。
go run 命令在第二次执行的时候,如果发现导入的代码包没有发生变化,那么 go run 不会再次编译这个导入的代码包。直接静态链接进来。
1 | localhost:hello ruby$ go run -n mytest.go |
2. go build
go build 命令主要是用于测试编译。在包的编译过程中,若有必要,会同时编译与之相关联的包。
- 如果是普通包,当你执行go build命令后,不会产生任何文件。
- 如果是main包,当只执行go build命令后,会在当前目录下生成一个可执行文件。如果需要在$GOPATH/bin目录下生成相应的exe文件,需要执行go install 或者使用 go build -o 路径/可执行文件。
- 如果某个文件夹下有多个文件,而你只想编译其中某一个文件,可以在 go build 之后加上文件名,例如 go build a.go;go build 命令默认会编译当前目录下的所有go文件。
- 你也可以指定编译输出的文件名。比如,我们可以指定go build -o 可执行文件名,默认情况是你的package名(非main包),或者是第一个源文件的文件名(main包)。
- go build 会忽略目录下以”_”或者”.”开头的go文件。
- 如果你的源代码针对不同的操作系统需要不同的处理,那么你可以根据不同的操作系统后缀来命名文件。
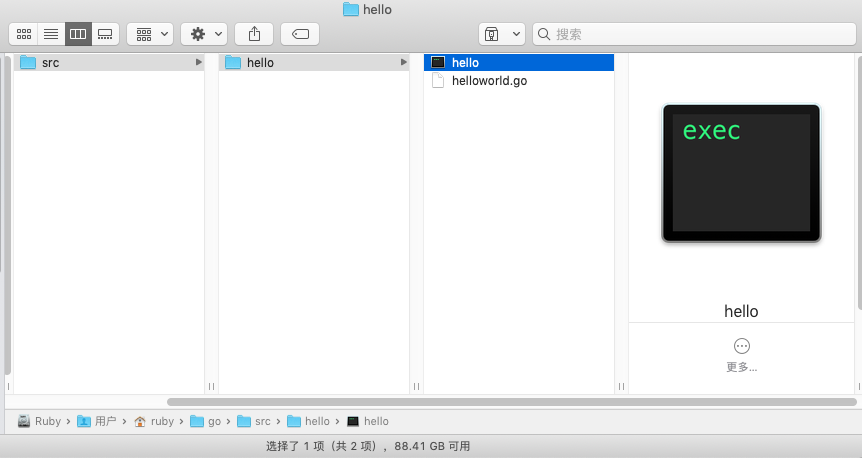
当代码包中有且仅有一个命令源码文件的时候,在文件夹所在目录中执行 go build 命令,会在该目录下生成一个与目录同名的可执行文件。
1 | // 假设当前文件夹名叫 hello |
于是在当前目录直接生成了以当前文件夹为名的可执行文件( 在 Mac 平台下是 Unix executable 文件,在 Windows 平台下是 exe 文件)
但是这种情况下,如果使用 go install 命令,如果 GOPATH 里面只有一个工作区,就会在当前工作区的 bin 目录下生成相应的可执行文件。如果 GOPATH 下有多个工作区,则是在 GOBIN 下生成对应的可执行文件。
1 | localhost:hello ruby$ go install |
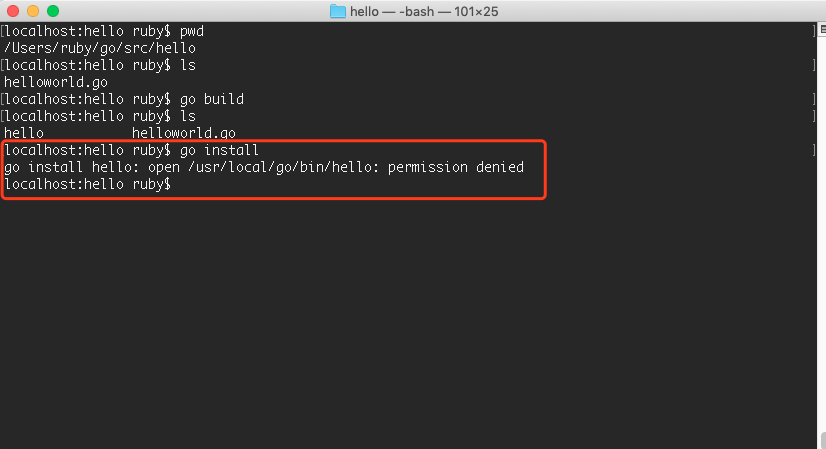
这个问题是因为它需要创建bin目录,然后把可刚才的可执行文件放进去,而目前我们在gopath下还没有bin目录,那么就需要先创建这个文件,而普通用户没有直接创建文件夹的权限,这个和Go语言的命令是没有关系的。我们可以加上sodu 来执行这个命令,表示使用管理员的身份执行,然后输入密码,那么就可以创建bin这个文件夹了。
再次执行:
1 | localhost:hello ruby$ sudo go install |
执行完 go install 会发现可执行文件不见了!去哪里了呢?其实是被移动到了 bin 目录下了(如果 GOPATH 下有多个工作区,就会放在GOBIN 目录下)。
查看目录:
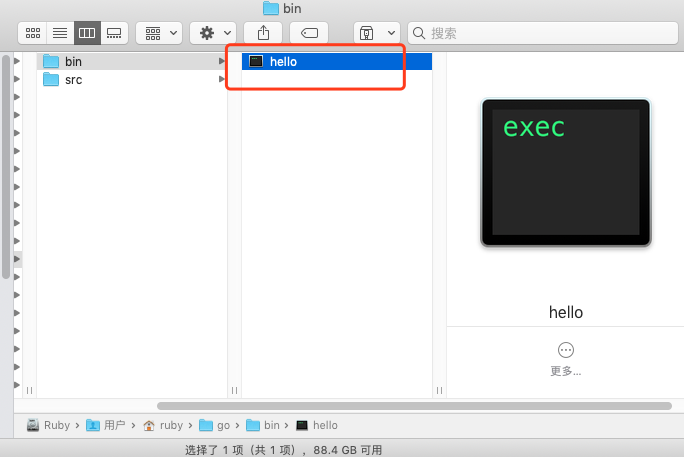
那 go build 和 go install 究竟干了些什么呢?
先来说说 go build。go build 用于编译我们指定的源码文件或代码包以及它们的依赖包。但是注意如果用来编译非命令源码文件,即库源码文件,go build 执行完是不会产生任何结果的。这种情况下,go build 命令只是检查库源码文件的有效性,只会做检查性的编译,而不会输出任何结果文件。
go build 编译命令源码文件,则会在该命令的执行目录中生成一个可执行文件,上面的例子也印证了这个过程。
go build 后面不追加目录路径的话,它就把当前目录作为代码包并进行编译。go build 命令后面如果跟了代码包导入路径作为参数,那么该代码包及其依赖都会被编译。
go build 命令究竟做了些什么呢?我们可以执行-n这个命令来查看:
1 | localhost:hello ruby$ go build -n |
可以看到,执行过程和 go run 大体相同,唯一不同的就是在最后一步,go run 是执行了可执行文件,但是 go build 命令,只是把库源码文件编译了一遍,然后把可执行文件移动到了当前目录的文件夹中。
总结一下如下图:
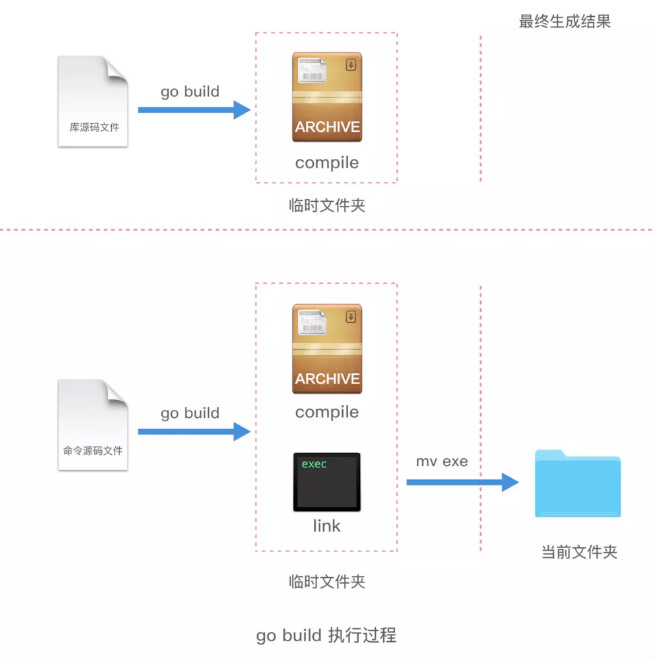
编译 使用go build
在项目目录下
在其他路径下执行go build, 需要在后面加上项目路径,从 gopath之后开始写
3. go install
go install 命令是用来编译并安装代码包或者源码文件的。
go install 命令在内部实际上分成了两步操作:第一步是生成结果文件(可执行文件或者.a包),第二步会把编译好的结果移到 $GOPATH/pkg或者 $GOPATH/bin。
可执行文件: 一般是 go install 带main函数的go文件产生的,有函数入口,所有可以直接运行。
.a应用包: 一般是 go install 不包含main函数的go文件产生的,没有函数入口,只能被调用。
go install 用于编译并安装指定的代码包及它们的依赖包。当指定的代码包的依赖包还没有被编译和安装时,该命令会先去处理依赖包。与 go build 命令一样,传给 go install 命令的代码包参数应该以导入路径的形式提供。并且,go build 命令的绝大多数标记也都可以用于
实际上,go install 命令只比 go build 命令多做了一件事,即:安装编译后的结果文件到指定目录。
安装代码包会在当前工作区的 pkg 的平台相关目录下生成归档文件(即 .a 文件)。
安装命令源码文件会在当前工作区的 bin 目录(如果 GOPATH 下有多个工作区,就会放在 GOBIN 目录下)生成可执行文件。
同样,go install 命令如果后面不追加任何参数,它会把当前目录作为代码包并安装。这和 go build 命令是完全一样的。
go install 命令后面如果跟了代码包导入路径作为参数,那么该代码包及其依赖都会被安装。
go install 命令后面如果跟了命令源码文件以及相关库源码文件作为参数的话,只有这些文件会被编译并安装。
go install 命令究竟做了些什么呢?
1 | localhost:hello ruby$ go install -n |
前面几步依旧和 go run 、go build 完全一致,只是最后一步的差别,go install 会把命令源码文件安装到当前工作区的 bin 目录(如果 GOPATH 下有多个工作区,就会放在 GOBIN 目录下)。如果是库源码文件,就会被安装到当前工作区的 pkg 的平台相关目录下。
总结一下如下图:
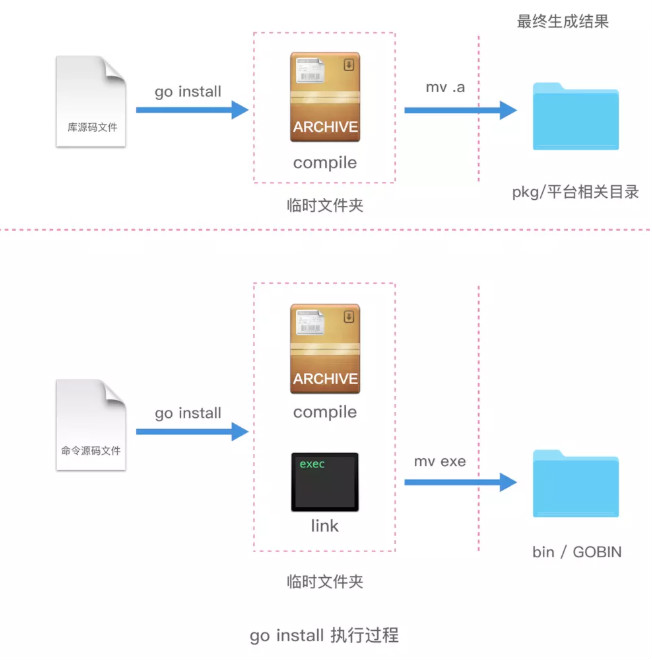
在安装多个库源码文件时有可能遇到如下的问题:
1 | localhost:hello ruby$ go install envir.go fpath.go ipath.go pnode.go util.go |
而且,在我们为环境变量 GOBIN 设置了正确的值之后,这个错误提示信息仍然会出现。这是因为,只有在安装命令源码文件的时候,命令程序才会将环境变量 GOBIN 的值作为结果文件的存放目录。而在安装库源码文件时,在命令程序内部的代表结果文件存放目录路径的那个变量不会被赋值。最后,命令程序会发现它依然是个无效的空值。所以,命令程序会同样返回一个关于“无安装位置”的错误。这就引出一个结论,我们只能使用安装代码包的方式来安装库源码文件,而不能在 go install 命令罗列并安装它们。另外,go install 命令目前无法接受标记 -o以自定义结果文件的存放位置。这也从侧面说明了
go install 命令不支持针对库源码文件的安装操作。
go 跨平台编译,交叉编译
4. go get
go get 命令用于从远程代码仓库(比如 Github )上下载并安装代码包。注意,go get 命令会把当前的代码包下载到 $GOPATH 中的第一个工作区的 src 目录中,并安装。
使用 go get 下载第三方包的时候,依旧会下载到 $GOPATH 的第一个工作空间,而非 vendor 目录。当前工作链中并没有真正意义上的包依赖管理,不过好在有不少第三方工具可选。
如果在 go get 下载过程中加入 -d 标记,那么下载操作只会执行下载动作,而不执行安装动作。比如有些非常特殊的代码包在安装过程中需要有特殊的处理,所以我们需要先下载下来,所以就会用到 -d 标记。
还有一个很有用的标记是 -u标记,加上它可以利用网络来更新已有的代码包及其依赖包。如果已经下载过一个代码包,但是这个代码包又有更新了,那么这时候可以直接用 -u标记来更新本地的对应的代码包。如果不加这个 -u标记,执行 go get 一个已有的代码包,会发现命令什么都不执行。只有加了 -u标记,命令会去执行 git pull 命令拉取最新的代码包的最新版本,下载并安装。
命令 go get 还有一个很值得称道的功能——智能下载。在使用它检出或更新代码包之后,它会寻找与本地已安装 Go 语言的版本号相对应的标签(tag)或分支(branch)。比如,本机安装 Go 语言的版本是1.x,那么 go get 命令会在该代码包的远程仓库中寻找名为 “go1” 的标签或者分支。如果找到指定的标签或者分支,则将本地代码包的版本切换到此标签或者分支。如果没有找到指定的标签或者分支,则将本地代码包的版本切换到主干的最新版本。
go get 常用的一些标记如下:
| 标记名称 | 标记描述 |
|---|---|
| -d | 让命令程序只执行下载动作,而不执行安装动作。 |
| -f | 仅在使用 -u标记时才有效。该标记会让命令程序忽略掉对已下载代码包的导入路径的检查。如果下载并安装的代码包所属的项目是你从别人那里 Fork 过来的,那么这样做就尤为重要了。 |
| -fix | 让命令程序在下载代码包后先执行修正动作,而后再进行编译和安装。 |
| -insecure | 允许命令程序使用非安全的 scheme(如 HTTP )去下载指定的代码包。如果你用的代码仓库(如公司内部的 Gitlab )没有HTTPS 支持,可以添加此标记。请在确定安全的情况下使用它。 |
| -t | 让命令程序同时下载并安装指定的代码包中的测试源码文件中依赖的代码包。 |
| -u | 让命令利用网络来更新已有代码包及其依赖包。默认情况下,该命令只会从网络上下载本地不存在的代码包,而不会更新已有的代码包。 |
go get 命令究竟做了些什么呢?我们还是来打印一下每一步的执行过程。
1 | localhost:hello ruby$ go get -x github.com/go-errors/errors |
效果图:
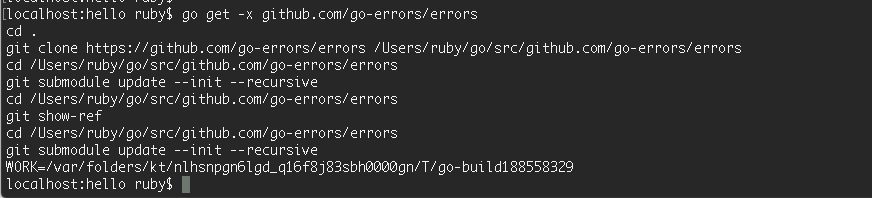
这里可以很明显的看到,执行完 go get 命令以后,会调用 git clone 方法下载源码,并编译,最终会把库源码文件编译成归档文件安装到 pkg 对应的相关平台目录下。
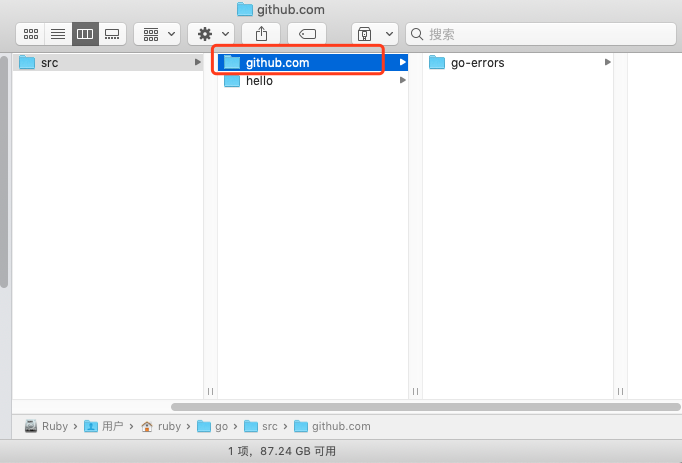
总结一下如下图:
5. 其他命令
go clean
go clean 命令是用来移除当前源码包里面编译生成的文件,这些文件包括
- _obj/ 旧的object目录,由Makefiles遗留
- _test/ 旧的test目录,由Makefiles遗留
- _testmain.go 旧的gotest文件,由Makefiles遗留
- test.out 旧的test记录,由Makefiles遗留
- build.out 旧的test记录,由Makefiles遗留
- *.[568ao] object文件,由Makefiles遗留
- DIR(.exe) 由 go build 产生
- DIR.test(.exe) 由 go test -c 产生
- MAINFILE(.exe) 由 go build MAINFILE.go产生
go fmt
go fmt 命令主要是用来帮你格式化所写好的代码文件。
比如我们写了一个格式很糟糕的 test.go 文件,我们只需要使用 fmt go test.go 命令,就可以让go帮我们格式化我们的代码文件。但是我们一般很少使用这个命令,因为我们的开发工具一般都带有保存时自动格式化功能,这个功能底层其实就是调用了 go fmt 命令而已。
使用go fmt命令,更多时候是用gofmt,而且需要参数-w,否则格式化结果不会写入文件。gofmt -w src,可以格式化整个项目。
go test
go test 命令,会自动读取源码目录下面名为*_test.go的文件,生成并运行测试用的可执行文件。默认的情况下,不需要任何的参数,它会自动把你源码包下面所有test文件测试完毕,当然你也可以带上参数,详情请参考go help testflag
go doc
go doc 命令其实就是一个很强大的文档工具。
如何查看相应package的文档呢? 例如builtin包,那么执行go doc builtin;如果是http包,那么执行go doc net/http;查看某一个包里面的函数,那么执行go doc fmt Printf;也可以查看相应的代码,执行go doc -src fmt Printf;
1 | 查看net/http包 |
通过命令在命令行执行 go doc -http=:端口号,比如godoc -http=:8080。然后在浏览器中打开127.0.0.1:8080,你将会看到一个golang.org的本地copy版本,通过它你可以查询pkg文档等其它内容。如果你设置了GOPATH,在pkg分类下,不但会列出标准包的文档,还会列出你本地GOPATH中所有项目的相关文档,这对于经常被限制访问的用户来说是一个不错的选择。
1 | localhost:hello ruby$ godoc -http=:9527 |
go fix 用来修复以前老版本的代码到新版本,例如go1之前老版本的代码转化到go1
go version 查看go当前的版本
go env 查看当前go的环境变量
go list 列出当前全部安装的package
Day1-10安装golang
1.1 使用Goland
创建项目:
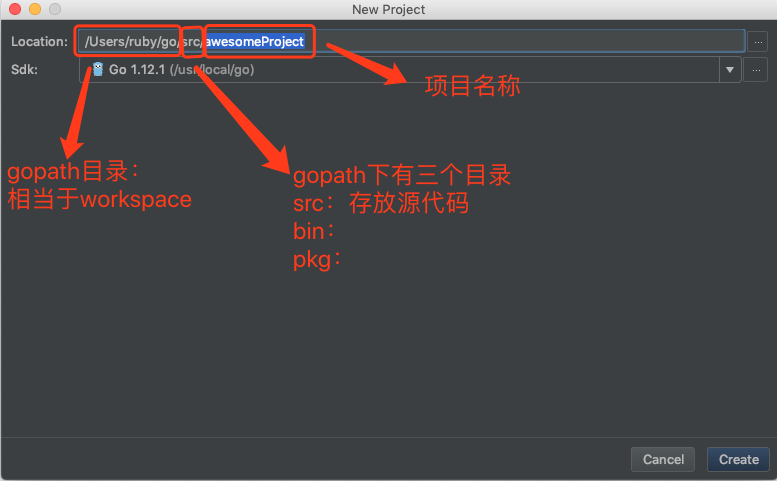
Goland配置goroot:
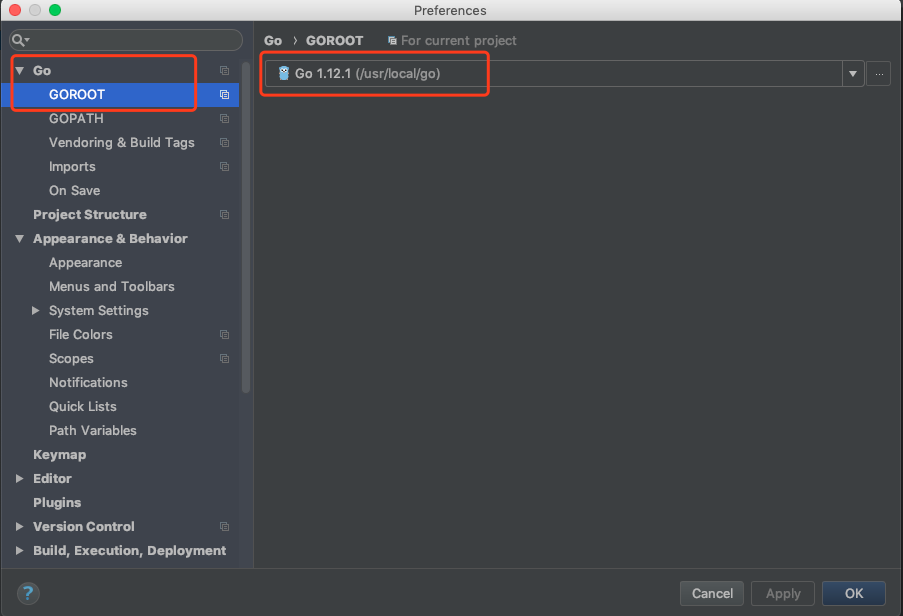
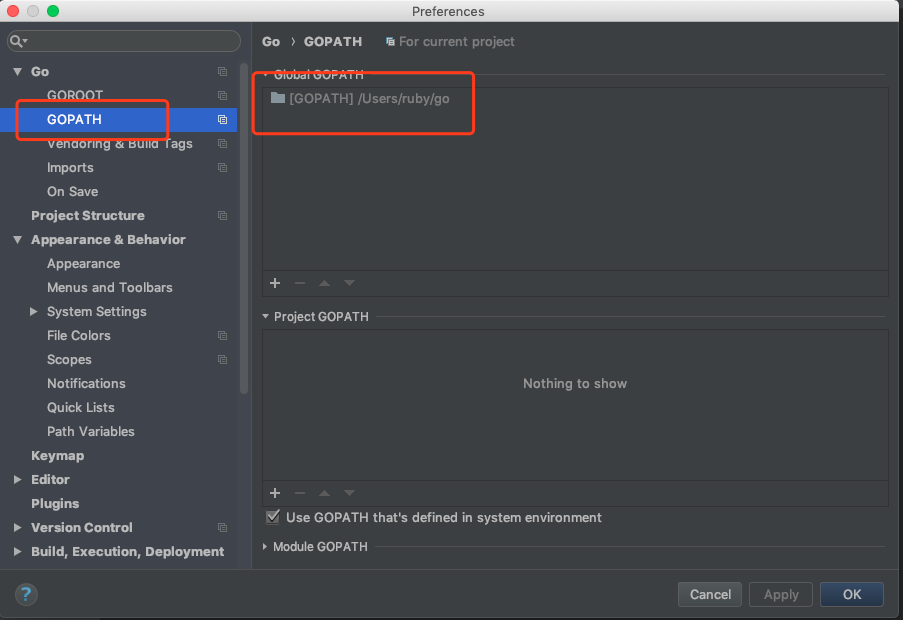
配置gopath:
1 | Goland常用快捷键 |
Ubuntu下安装GoLand工具
首先下载GoLand软件到下载文件夹下。然后在终端输入以下命令:
1 | ruby@ubuntu:~/下载$ sudo tar -xzf goland-2017.3.3.tar.gz -C /opt |
进入bin目录下执行以下命令:
1 | ruby@ubuntu:/opt/GoLand-2017.3.3/bin$ sh goland.sh |
Day01-11编码规范
一、 命名规范
Go在命名时以字母a到Z或a到Z或下划线开头,后面跟着零或更多的字母、下划线和数字(0到9)。Go不允许在命名时中使用@、$和%等标点符号。Go是一种区分大小写的编程语言。因此,Manpower和manpower是两个不同的命名。
- 当命名(包括常量、变量、类型、函数名、结构字段等等)以一个大写字母开头,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的 public);
- 命名如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的 private )
1、包命名:package
保持package的名字和目录保持一致,尽量采取有意义的包名,简短,有意义,尽量和标准库不要冲突。包名应该为小写单词,不要使用下划线或者混合大小写。
1 | package demo |
2、 文件命名
尽量采取有意义的文件名,简短,有意义,应该为小写单词,使用下划线分隔各个单词。
1 | my_test.go |
3、 结构体命名
- 采用驼峰命名法,首字母根据访问控制大写或者小写
- struct 申明和初始化格式采用多行,例如下面:
1 | // 多行申明 |
4、 接口命名
- 命名规则基本和上面的结构体类型
- 单个函数的结构名以 “er” 作为后缀,例如 Reader , Writer 。
1 | type Reader interface { |
5、变量命名
- 和结构体类似,变量名称一般遵循驼峰法,首字母根据访问控制原则大写或者小写,但遇到特有名词时,需要遵循以下规则:
- 如果变量为私有,且特有名词为首个单词,则使用小写,如 apiClient
- 其它情况都应当使用该名词原有的写法,如 APIClient、repoID、UserID
- 错误示例:UrlArray,应该写成 urlArray 或者 URLArray
- 若变量类型为 bool 类型,则名称应以 Has, Is, Can 或 Allow 开头
1 | var isExist bool |
6、常量命名
常量均需使用全部大写字母组成,并使用下划线分词
1 | const APP_VER = "1.0" |
如果是枚举类型的常量,需要先创建相应类型:
1 | type Scheme string |
7、 关键字
Go中的保留字不能用作常量或变量或任何其他标识符名称。
二、注释
Go提供C风格的 /* */块注释和C ++风格的 //行注释。行注释是常态;块注释主要显示为包注释,但在表达式中很有用或禁用大量代码。
- 单行注释是最常见的注释形式,你可以在任何地方使用以 // 开头的单行注释
- 多行注释也叫块注释,均已以 /* 开头,并以 */ 结尾,且不可以嵌套使用,多行注释一般用于包的文档描述或注释成块的代码片段
go 语言自带的 godoc 工具可以根据注释生成文档,生成可以自动生成对应的网站( golang.org 就是使用 godoc 工具直接生成的),注释的质量决定了生成的文档的质量。每个包都应该有一个包注释,在package子句之前有一个块注释。对于多文件包,包注释只需要存在于一个文件中,任何一个都可以。包评论应该介绍包,并提供与整个包相关的信息。它将首先出现在 godoc页面上,并应设置下面的详细文档。
详细的如何写注释可以
参考:http://golang.org/doc/effective_go.html#commentary
1、包注释
每个包都应该有一个包注释,一个位于package子句之前的块注释或行注释。包如果有多个go文件,只需要出现在一个go文件中(一般是和包同名的文件)即可。 包注释应该包含下面基本信息(请严格按照这个顺序,简介,创建人,创建时间):
- 包的基本简介(包名,简介)
- 创建者,格式: 创建人: rtx 名
- 创建时间,格式:创建时间: yyyyMMdd
例如 util 包的注释示例如下
1 | // util 包, 该包包含了项目共用的一些常量,封装了项目中一些共用函数。 |
2、结构(接口)注释
每个自定义的结构体或者接口都应该有注释说明,该注释对结构进行简要介绍,放在结构体定义的前一行,格式为: 结构体名, 结构体说明。同时结构体内的每个成员变量都要有说明,该说明放在成员变量的后面(注意对齐),实例如下:
1 | // User , 用户对象,定义了用户的基础信息 |
3、函数(方法)注释
每个函数,或者方法(结构体或者接口下的函数称为方法)都应该有注释说明,函数的注释应该包括三个方面(严格按照此顺序撰写):
- 简要说明,格式说明:以函数名开头,“,”分隔说明部分
- 参数列表:每行一个参数,参数名开头,“,”分隔说明部分
- 返回值: 每行一个返回值
示例如下:
1 | // NewtAttrModel , 属性数据层操作类的工厂方法 |
4、代码逻辑注释
对于一些关键位置的代码逻辑,或者局部较为复杂的逻辑,需要有相应的逻辑说明,方便其他开发者阅读该段代码,实例如下:
1 | // 从 Redis 中批量读取属性,对于没有读取到的 id , 记录到一个数组里面,准备从 DB 中读取 |
5、注释风格
统一使用中文注释,对于中英文字符之间严格使用空格分隔, 这个不仅仅是中文和英文之间,英文和中文标点之间也都要使用空格分隔,例如:
1 | // 从 Redis 中批量读取属性,对于没有读取到的 id , 记录到一个数组里面,准备从 DB 中读取 |
上面 Redis 、 id 、 DB 和其他中文字符之间都是用了空格分隔。
- 建议全部使用单行注释
- 和代码的规范一样,单行注释不要过长,禁止超过 120 字符。
三、代码风格
1、缩进和折行
- 缩进直接使用 gofmt 工具格式化即可(gofmt 是使用 tab 缩进的);
- 折行方面,一行最长不超过120个字符,超过的请使用换行展示,尽量保持格式优雅。
我们使用Goland开发工具,可以直接使用快捷键:ctrl+alt+L,即可。
2、语句的结尾
Go语言中是不需要类似于Java需要冒号结尾,默认一行就是一条数据
如果你打算将多个语句写在同一行,它们则必须使用 ;
3、括号和空格
括号和空格方面,也可以直接使用 gofmt 工具格式化(go 会强制左大括号不换行,换行会报语法错误),所有的运算符和操作数之间要留空格。
1 | // 正确的方式 |
4、import 规范
import在多行的情况下,goimports会自动帮你格式化,但是我们这里还是规范一下import的一些规范,如果你在一个文件里面引入了一个package,还是建议采用如下格式:
1 | import ( |
如果你的包引入了三种类型的包,标准库包,程序内部包,第三方包,建议采用如下方式进行组织你的包:
1 | import ( |
有顺序的引入包,不同的类型采用空格分离,第一种实标准库,第二是项目包,第三是第三方包。
在项目中不要使用相对路径引入包:
1 | // 这是不好的导入 |
但是如果是引入本项目中的其他包,最好使用相对路径。
5、错误处理
- 错误处理的原则就是不能丢弃任何有返回err的调用,不要使用 _ 丢弃,必须全部处理。接收到错误,要么返回err,或者使用log记录下来
- 尽早return:一旦有错误发生,马上返回
- 尽量不要使用panic,除非你知道你在做什么
- 错误描述如果是英文必须为小写,不需要标点结尾
- 采用独立的错误流进行处理
1 | // 错误写法 |
6、测试
单元测试文件名命名规范为 example_test.go
测试用例的函数名称必须以 Test 开头,例如:TestExample
每个重要的函数都要首先编写测试用例,测试用例和正规代码一起提交方便进行回归测试
四、常用工具
上面提到了很过规范, go 语言本身在代码规范性这方面也做了很多努力,很多限制都是强制语法要求,例如左大括号不换行,引用的包或者定义的变量不使用会报错,此外 go 还是提供了很多好用的工具帮助我们进行代码的规范,
gofmt
大部分的格式问题可以通过gofmt解决, gofmt 自动格式化代码,保证所有的 go 代码与官方推荐的格式保持一致,于是所有格式有关问题,都以 gofmt 的结果为准。
goimport
我们强烈建议使用 goimport ,该工具在 gofmt 的基础上增加了自动删除和引入包.
1 | go get golang.org/x/tools/cmd/goimports |
go vet
vet工具可以帮我们静态分析我们的源码存在的各种问题,例如多余的代码,提前return的逻辑,struct的tag是否符合标准等。
1 | go get golang.org/x/tools/cmd/vet |
使用如下:
1 | go vet . |
值类型&引用类型
值类型 :改变变量副本值的时候,不会改变变量本身的值 (基本数据类型、数组)
引用类型:改变变量副本值的时候,会改变变量本身的值 (切片、map)
1 | 一:数据类型: |
1 | 每种数据类型的零值: |
1 | make() |
Day02 基本语法——变量
一、声明变量
变量命名规则:以字母或下划线开头,后接字母数字下划线(a-zA-Z0-9_)
go关键字:
1 | break default func interface select |
go保留字:
1 | Constants: true false iota nil |
程序运行过程中的数据都是保存在内存中,我们想要在代码中操作某个数据时就需要去内存上找到这个变量,但是如果我们直接在代码中通过内存地址去操作变量的话,代码的可读性会非常差而且还容易出错,所以我们就利用变量将这个数据的内存地址保存起来,以后直接通过这个变量就能找到内存上对应的数据了。
经过半个多世纪的发展,编程语言已经基本形成了一套固定的类型,常见变量的数据类型有:整型、浮点型、布尔型等。Go语言中的每一个变量都有自己的类型,并且变量必须经过声明才能开始使用,同一作用域内不支持重复声明。 并且Go语言的变量声明后必须使用。
1.1单变量声明
第一种,指定变量类型,声明后若不赋值,使用默认值
1 | var name type |
第二种,根据值自行判定变量类型(类型推断Type inference)
如果一个变量有一个初始值,Go将自动能够使用初始值来推断该变量的类型。因此,如果变量具有初始值,则可以省略变量声明中的类型。
1 | var name1 string = value |
第三种,省略var, 注意 :=左侧的变量不应该是已经声明过的(多个变量同时声明时,至少保证一个是新变量),否则会导致编译错误(简短声明)。这种方式它只能被用在函数体内,而不可以用于全局变量的声明与赋值。
1 | name := value |
变量的声明过程分为:变量声明和变量赋值;:= 的作用是声明并赋值,而变量是无法二次声明的,所以如果采用多变量声明的话,:= 左边必须有一个新变量,这个新变量是 声明、赋值,其他的变量是赋值。
1.2多变量声明
第一种,以逗号分隔,声明与赋值分开,若不赋值,存在默认值
1 | var name1, name2, name3 type |
第二种,直接赋值,下面的变量类型可以是不同的类型
在一行书写的多变量声明,如果多个变量是不同的类型的话,只能采用“声明并且赋值”的方式。只声明,不赋值的形式,只能声明同一种类型
1 | var name2, age2 = "沙河娜扎", 28 |
第三种,集合类型
1 | //批量声明变量 |
如果使用集合声明,则书写就较为随意:可以同时声明多种类型,也可以随意给任何变量赋值或者不赋值
1 | a := 3 |
1.3注意事项
- 变量必须先定义才能使用
- go语言是静态语言,要求变量的类型和赋值的类型必须一致。
- 变量名不能冲突。(同一个作用于域内不能冲突)
- 简短定义方式,左边的变量名至少有一个是新的
- 简短定义方式,不能定义全局变量。
- 变量的零值。也叫默认值。
- 变量定义了就要使用,否则无法通过编译。
- 再次赋值时,不能改变变量的类型
- 函数外的每个语句都必须以关键字开始(var、const、func等)
:=不能使用在函数外。_多用于占位,表示忽略值,匿名变量。
1 | Go语言在声明变量的时候,会自动对变量对应的内存区域进行初始化操作。每个变量会被初始化成其类型的默认值。 |
如果在相同的代码块中,我们不可以再次对于相同名称的变量使用初始化声明,例如:a := 20 就是不被允许的,编译器会提示错误 no new variables on left side of :=,但是 a = 20 是可以的,因为这是给相同的变量赋予一个新的值。
同一个变量,不能多次声明;声明变量,相当于开辟内存
如果你在定义变量 a 之前使用它,则会得到编译错误 undefined: a。如果你声明了一个局部变量(无论赋值与否,赋值是写变量)却没有在相同的代码块中使用它(读这个变量),同样会得到编译错误。
常亮或全局变量,未使用不会报错
在同一个作用域中,已存在同名的变量,则之后的声明初始化,则退化为赋值操作。但这个前提是,最少要有一个新的变量被定义,且在同一作用域。
在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量(anonymous variable)。 匿名变量用一个下划线_表示。匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明。
二、常量的使用
1.1 常量声明
常量是一个简单值的标识符,在程序运行时,不会被修改的量。
1 | const identifier [type] = value |
1 | 显式类型定义: const b string = "abc" |
1 | package main |
运行结果:
1 | 面积为 : 50 |
常量可以作为枚举,常量组
1 | const ( |
常量组中如不指定类型和初始化值,则与上一行非空常量右值相同
1 | package main |
运行结果:
1 | uint16,16 |
常量的注意事项:
- 常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型
- 不曾使用的常量,在编译的时候,是不会报错的
- 显示指定类型的时候,必须确保常量左右值类型一致,需要时可做显示类型转换。
1.2 iota
iota,特殊常量,可以认为是一个可以被编译器修改的常量,只能用在常量表达式中
iota 可以被用作枚举值:
1 | const ( |
第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1;所以 a=0, b=1, c=2 可以简写为如下形式:
1 | const ( |
iota 用法
1 | package main |
运行结果:
1 | 0 1 2 ha ha 100 100 7 8 |
如果中断iota自增,则必须显式恢复。且后续自增值按行序递增
自增默认是int类型,可以自行进行显示指定类型
数字常量不会分配存储空间,无须像变量那样通过内存寻址来取值,因此无法获取地址。
只要有iota,那么常量就会从0开始基数;与何时声明iota无关。
常见iota类型:
1 | const ( |
Day03-1数据类型&运算符
1 | Go语言的数据类型: |
一、基本数据类型
以下是go中可用的基本数据类型

1.1 布尔型bool
布尔型的值只可以是常量 true 或者 false。一个简单的例子:var b bool = true
1.2 数值型
1、整数型
1 | 有符号:最高位表示符号位,0正数,1负数,其余位表示数值 |
int和uint:根据底层平台,表示32或64位整数。除非需要使用特定大小的整数,否则通常应该使用int来表示整数。
大小:32位系统32位,64位系统64位。
范围:-2147483648到2147483647的32位系统和-9223372036854775808到9223372036854775807的64位系统。语法上,int/int32/int64是不同的数据类型。
2、浮点型
float32
IEEE-754 32位浮点型数
float64
IEEE-754 64位浮点型数
complex64
32 位实数和虚数
complex128
64 位实数和虚数
3、其他
byte => uint8
rune => int32
uint =>32 或 64 位
int => uint 一样大小
uintptr =>无符号整型,用于存放一个指针
1 | func main() { |
1.3 字符串型
字符串就是一串固定长度的字符连接起来的字符序列。Go的字符串是由单个字节连接起来的。Go语言的字符串的字节使用UTF-8编码标识Unicode文本
多个byte的集合,使用双引号或者反引号`
1 | var str string |
‘A’ 表示为一个数字,为对应的utf8编码值。
Go语言中要定义一个多行字符串时,就必须使用反引号字符:
1 | s1 := `第一行 |
反引号中所有的转义字符均无效,文本将会原样输出。
字符串的常用操作
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
| +或fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割 |
| strings.contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置 |
| strings.Join(a[]string, sep string) | join操作 |
1.5byte和rune类型
组成每个字符串的元素叫做“字符”,可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号(’)包裹起来,如:
1 | var a = '中' |
Go 语言的字符有以下两种:
uint8类型,或者叫 byte 型,代表一个ASCII码字符。rune类型,代表一个UTF-8字符。
当需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型实际是一个int32。
Go 使用了特殊的 rune 类型来处理 Unicode,让基于 Unicode 的文本处理更为方便,也可以使用 byte 型进行默认字符串处理,性能和扩展性都有照顾。
1 | // 遍历字符串 |
输出:
1 | 104(h) 101(e) 108(l) 108(l) 111(o) 230(æ) 178(²) 153() 230(æ) 178(²) 179(³) |
因为UTF8编码下一个中文汉字由3~4个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串,否则就会出现上面输出中第一行的结果。
字符串底层是一个byte数组,所以可以和[]byte类型相互转换。字符串是不能修改的。字符串是由byte字节组成,所以字符串的长度是byte字节的长度。 rune类型用来表示utf8字符,一个rune字符由一个或多个byte组成。
1.6修改字符串
要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
1 | func changeString() { |
1.4 数据类型转换:Type Convert
Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用。
语法格式:Type(Value)。T表示要转换的类型。表达式包括变量、复杂算子和函数返回值等。
常数:在有需要的时候,会自动转型
变量:需要手动转型 T(V)
注意点:兼容类型可以转换
1 | strconv |
1 | // 比如计算直角三角形的斜边长时使用math包的Sqrt()函数,该函数接收的是float64类型的参数,而变量a和b都是int类型的,这个时候就需要将a和b强制类型转换为float64类型。 |
二、复合类型(派生类型)
1、指针类型(Pointer)
2、数组类型
3、结构化类型(struct)
4、Channel 类型
5、函数类型
6、切片类型
7、接口类型(interface)
8、Map 类型
1 | array,slice,map,function,pointer,struct,interface,channel。。。 |
三、运算符
表达式:(a + b) * c
a,b,c叫做操作数
+,*,叫做运算符
1.1 算术运算符
1 | + - * / %(求余) ++ -- |
1.2 关系运算符
1 | == != > < >= <= |
1.3 逻辑运算符
1 | && || ! |
1.4 位运算符
这里最难理解的就是^了,只要认为AB两者都相同的时候,为0,其他都为1
A为60-0110 0000
B为13-0001 0011
| 运算 | 描述 | 示例 |
|---|---|---|
| & | 两位均为1才为1 | (A & B) = 12, 也就是 0000 1100 |
| | | 两位有一个为1就为1 | (A| B) = 61, 也就是 0011 1101 |
| ^ | 两位不一样则为1 | (A ^ B) = 49, 也就是 0011 0001 |
| &^ | 它会将第一个操作数中,对应第二个操作数为 1 的位清零。 | (A&^B)=48,也就是0110 000 |
| << | 二进制左移位运算符。左边的操作数的值向左移动由右操作数指定的位数 | A << 2 =240 也就是 1111 0000 |
| >> | 二进制向右移位运算符。左边的操作数的值由右操作数指定的位数向右移动 | A >> 2 = 15 也就是 0000 1111 |
1.5 赋值运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
| = | 简单的赋值操作符,分配值从右边的操作数左侧的操作数 | C = A + B 将分配A + B的值到C |
| += | 相加并赋值运算符,它增加了右操作数左操作数和分配结果左操作数 | C += A 相当于 C = C + A |
| -= | 减和赋值运算符,它减去右操作数从左侧的操作数和分配结果左操作数 | C -= A 相当于 C = C - A |
| *= | 乘法和赋值运算符,它乘以右边的操作数与左操作数和分配结果左操作数 | C *= A 相当于 C = C * A |
| /= | 除法赋值运算符,它把左操作数与右操作数和分配结果左操作数 | C /= A 相当于 C = C / A |
| %= | 模量和赋值运算符,它需要使用两个操作数的模量和分配结果左操作数 | C %= A 相当于 C = C % A |
| <<= | 左移位并赋值运算符 | C <<= 2 相同于 C = C << 2 |
| >>= | 向右移位并赋值运算符 | C >>= 2 相同于 C = C >> 2 |
| &= | 按位与赋值运算符 | C &= 2 相同于 C = C & 2 |
| ^= | 按位异或并赋值运算符 | C ^= 2 相同于 C = C ^ 2 |
| |= | 按位或并赋值运算符 | C|= 2 相同于 C = C | 2 |
1.6优先级运算符优先级
有些运算符拥有较高的优先级,二元运算符的运算方向均是从左至右。下表列出了所有运算符以及它们的优先级,由上至下代表优先级由高到低:
| 优先级 | 运算符 |
|---|---|
| 7 | ~ ! ++ – |
| 6 | * / % << >> & &^ |
| 5 | + - ^ |
| 4 | == != < <= >= > |
| 3 | <- |
| 2 | && |
| 1 | || |
当然,你可以通过使用括号来临时提升某个表达式的整体运算优先级。
1 | go的逻辑计算是短路计算的 |
Day03-2键盘输入和打印输出
一、打印输出
1.1 fmt包
fmt包实现了类似C语言printf和scanf的格式化I/O。
格式化打印:
func Printf(format string, a …interface{}) (n int, err error)
格式化打印中的常用占位符:
1 | %v,原样输出 |
二、键盘输入
2.1 fmt包读取键盘输入
常用方法:
func Scan(a …interface{}) (n int, err error)
func Scanf(format string, a …interface{}) (n int, err error)
func Scanln(a …interface{}) (n int, err error)
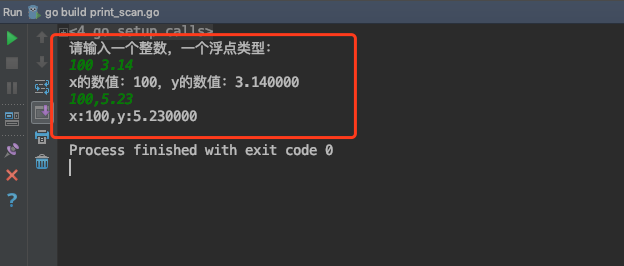
1 | package main |
运行结果:
2.2 bufio包读取
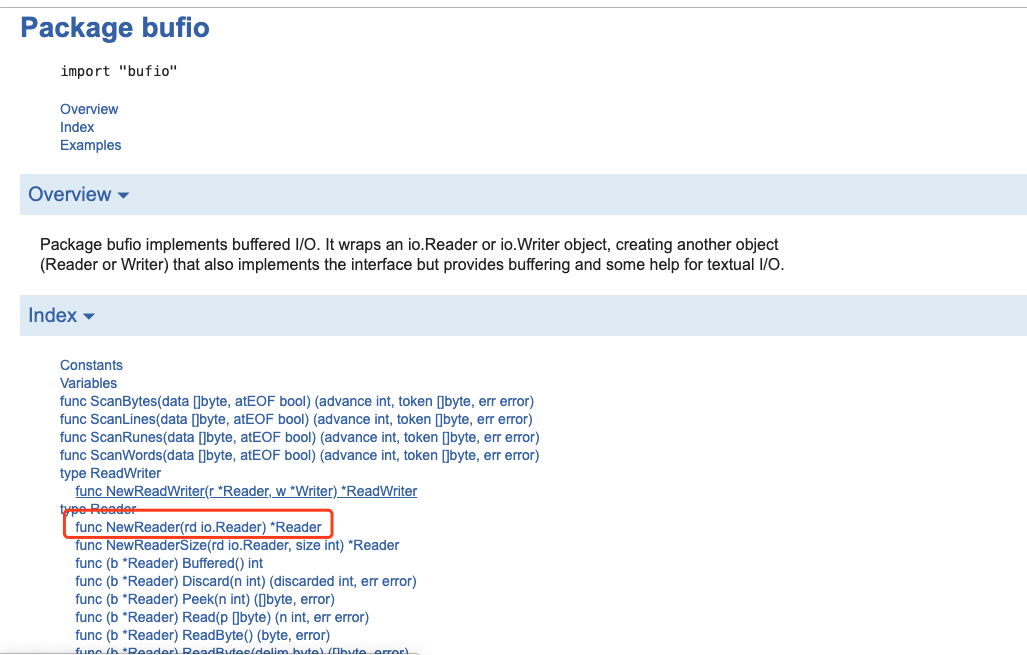
https://golang.google.cn/pkg/bufio/
bufio包中都是IO操作的方法:
先创建Reader对象:
然后就可以各种读取了:
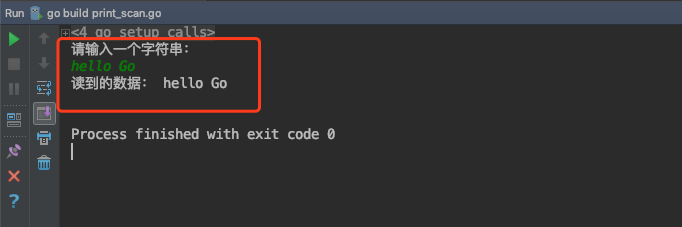
示例代码:
1 | package main |
运行效果:
随机字符串需要设置一个Seed种子才可以生成真正的随机数。
Day04 流程控制
选择结构:条件满足,某些代码才会执行。0-1次
分支语句:if,switch,select
循环结构:条件满足,某些代码会被反复的执行多次。0-N次
循环语句:for
一、选择流程结构
2.1 if 语句
语法格式:
1 | if 布尔表达式 { |
1 | if 布尔表达式 { |
1 | if 布尔表达式1 { |
如果其中包含一个可选的语句组件(在评估条件之前执行),则还有一个变体。它的语法是:
1 | package main |
需要注意的是,num的定义在if里,那么只能够在该if..else语句块中使用,否则编译器会报错的。
2.3 switch语句:“开关”
switch是一个条件语句,每一个 case 分支都是唯一的,从上直下逐一测试,直到匹配为止。
而如果switch没有表达式,它会匹配true
Go里面switch默认相当于每个case最后带有break,匹配成功后不会自动向下执行其他case,而是跳出整个switch, 但是可以使用fallthrough强制执行后面的case代码。
示例代码:
1 | package main |
1 | func switchDemo4() { |
2.4 fallthrough
如需贯通后续的case,就添加fallthrough
1 | package main |
运行结果:
1 | 15 |
case中的表达式是可选的,可以省略。如果该表达式被省略,则被认为是switch true,并且每个case表达式都被计算为true,并执行相应的代码块。
示例代码:
1 | package main |
1 | switch的类型包括:各个整形,浮点型-会有精度问题,字符串,布尔,对上述基本类型做了自定义的自定义类型,类型断言 |
2.5 Type Switch
switch 语句还可以被用于 type-switch 来判断某个 interface 变量中实际存储的变量类型。
1 | package main |
运行结果:
1 | x 的类型 :<nil> |
二、循环语句
循环语句表示条件满足,可以反复的执行某段代码。
for是唯一的循环语句。(Go没有while循环)
2.1 for语句
语法结构:
1 | for init; condition; post { } |
初始化语句只执行一次。在初始化循环之后,将检查该条件。如果条件计算为true,那么{}中的循环体将被执行,然后是post语句。post语句将在循环的每次成功迭代之后执行。在执行post语句之后,该条件将被重新检查。如果它是正确的,循环将继续执行,否则循环终止。
条件中只能使用:=进行赋值
示例代码:
1 | package main |
在for循环中声明的变量仅在循环范围内可用。因此,i不能在外部访问循环。
2.2 for循环变体
所有的三个组成部分,即初始化、条件和post都是可选的。
1 | for condition { } 效果与while相似 |
1 | for { } 无限循环 |
for 循环的 range 格式可以对 slice、map、数组、字符串等进行迭代循环
1 | for key, value := range oldMap { |
1 | package main |
运行结果:
1 | a 的值为: 0 |
2.2 多层for循环
for循环中又有循环嵌套,就表示多层循环了。
三、跳出循环的语句,可以增加标签
1、 break语句
break:跳出循环体。break语句用于在结束其正常执行之前突然终止for循环
示例代码:
1 | package main |
1 | func breakDemo1() { |
2、continue语句
continue:跳出一次循环。continue语句用于跳过for循环的当前迭代。在continue语句后面的for循环中的所有代码将不会在当前迭代中执行。循环将继续到下一个迭代。
示例代码:
1 | package main |
1 | func continueDemo() { |
3.goto语句
goto:可以无条件地转移到过程中指定的行。
Go语言中使用goto语句能简化一些代码的实现过程。 例如双层嵌套的for循环要退出时。
语法结构:
1 | goto label; |
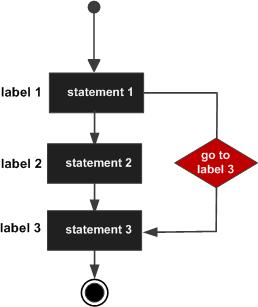
1 | package main |
统一错误处理
多处错误处理存在代码重复时是非常棘手的,例如:
1 | err := firstCheckError() |
随机数:生成的随机数是一样的;如果想要随机,需要设置种子数。
rand.Seed(time.Now().Unix())
rand.Seed()
4.for range
Go语言中可以使用for range遍历数组、切片、字符串、map 及通道(channel)。 通过for range遍历的返回值有以下规律:
- 数组、切片、字符串返回索引和值。
- map返回键和值。
- 通道(channel)只返回通道内的值。
Go1.22版本开始支持 for range 整数。
集合类型
数组 Array
数组是同一种数据类型元素的集合,数组从声明时就确定,使用时可以修改数组成员,但是数组大小不可变化。数组的长度必须是常量,并且长度是数组类型的一部分。一旦定义,长度不能变。 [5]int和[10]int是不同的类型。
1 | var variable_name [SIZE] variable_type |
数组声明时,需要指明数组的大小和存储的数据类型。
示例代码:
1 | var balance [10] float32 |
初始化数组中 {} 中的元素个数不能大于 [] 中的数字。
如果忽略 [] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大小:
1 | var balance = []float32{1000.0, 2.0, 3.4, 7.0, 50.0} |
1 | balance[4] = 50.0 |
数组的其他创建方式:
1 | var a [4] float32 // 等价于:var arr2 = [4]float32{} |
访问数组元素
1 | float32 salary = balance[9] |
示例代码:
1 | package main |
运行结果:
1 | Element[0] = 100 |
数组的长度
通过将数组作为参数传递给len函数,可以获得数组的长度。
示例代码:
1 | package main |
运行结果:
1 | length of a is 4 |
您甚至可以忽略声明中数组的长度并将其替换为…让编译器为你找到长度。这是在下面的程序中完成的。
示例代码:
1 | package main |
遍历数组:
1 | package main |
使用range遍历数组:
1 | package main |
如果您只需要值并希望忽略索引,那么可以通过使用_ blank标识符替换索引来实现这一点。
1 | for _, v := range a { //ignores index |
1.3 多维数组
Go 语言支持多维数组,以下为常用的多维数组声明语法方式:
1 | var variable_name [SIZE1][SIZE2]...[SIZEN] variable_type |
1 | var threedim [5][10][4]int |
三维数组
1 | a = [3][4]int{ |
1.4 数组是值类型
数组是值类型
Go中的数组是值类型,而不是引用类型。这意味着当它们被分配给一个新变量时,将把原始数组的副本分配给新变量。如果对新变量进行了更改,则不会在原始数组中反映。
1 | package main |
运行结果:
1 | a is [USA China India Germany France] |
数组的大小是类型的一部分。因此[5]int和[25]int是不同的类型。因此,数组不能被调整大小。不要担心这个限制,因为切片的存在是为了解决这个问题。
1 | package main |
数组的比较:
1 | func main() { |
1 | len(arr1), cap(arr1)) |
Slice
切片本身没有任何数据。它们只是对现有数组的引用。
从概念上面来说slice像一个结构体,这个结构体包含了三个元素:
- 指针,指向数组中slice指定的开始位置
- 长度,即slice的长度
- 最大长度,也就是slice开始位置到数组的最后位置的长度
切片拥有自己的长度和容量,我们可以通过使用内置的len()函数求长度,使用内置的cap()函数求切片的容量。
切片表达式从字符串、数组、指向数组或切片的指针构造子字符串或切片。它有两种变体:一种指定low和high两个索引界限值的简单的形式,另一种是除了low和high索引界限值外还指定容量的完整的形式。
切片的底层就是一个数组,所以我们可以基于数组通过切片表达式得到切片。 切片表达式中的low和high表示一个索引范围(左包含,右不包含),也就是下面代码中从数组a中选出1<=索引值<4的元素组成切片s,得到的切片长度=high-low,容量等于得到的切片的底层数组的容量。
Slice声明及初始化方法
1 | func initSlice() { |
切片默认值为nil,为引用类型,不能使用==,==只能和nil比较
1 | // 声明切片类型 |
1 | 要检查切片是否为空,请始终使用len(s) == 0来判断,而不应该使用s == nil来判断。 |
1.3 修改切片
slice没有自己的任何数据。它只是底层数组的一个表示。对slice所做的任何修改都将反映在底层数组中。
示例代码:
1 | package main |
运行结果:
1 | array before [57 89 90 82 100 78 67 69 59] |
当多个片共享相同的底层数组时,每个元素所做的更改将在数组中反映出来。
示例代码:
1 | package main |
运行结果:
1 | array before change 1 [78 79 80] |
1.4 len() 和 cap() 函数
切片的长度是切片中元素的数量。切片的容量是从创建切片的索引开始的底层数组中元素的数量。
切片是可索引的,并且可以由 len() 方法获取长度
切片提供了计算容量的方法 cap() 可以测量切片最长可以达到多少
1 | package main |
运行结果
1 | len=3 cap=5 slice=[0 0 0] |
空切片
一个切片在未初始化之前默认为 nil,长度为 0
1 | package main |
运行结果
1 | len=0 cap=0 slice=[] |
1 | package main |
运行结果
1 | len=9 cap=9 slice=[0 1 2 3 4 5 6 7 8] |
1.5 append() 和 copy() 函数
append 向slice里面追加一个或者多个元素,然后返回一个和slice一样类型的slice
copy 函数copy从源slice的src中复制元素到目标dst,并且返回复制的元素的个数
append函数会改变slice所引用的数组的内容,从而影响到引用同一数组的其它slice。 但当slice中没有剩余空间(即(cap-len) == 0)时,此时将动态分配新的数组空间。返回的slice数组指针将指向这个空间,而原数组的内容将保持不变;其它引用此数组的slice则不受影响。
内建函数append()可以为切片动态添加元素。 可以一次添加一个元素,可以添加多个元素,也可以添加另一个切片中的元素(后面加…)。
1 | 扩容逻辑: |
slice是引用类型,不能使用==,==只能和nil比较。
map
1.1 什么是Map
Map 是一种集合,是无序的,是引用类型,必须初始化才能使用。
map的key可以是所有可比较的类型,如布尔型、整数型、浮点型、复杂型、字符串型……也可以键。
1.2.1 创建map
可以使用内建函数 make, 也可以使用 map 关键字来定义 Map:
1 | /* 声明变量,默认 map 是 nil */ |
1 | //1.创建map |
delete(map, key) 函数用于删除集合的元素, 参数为 map 和其对应的 key。删除函数不返回任何值。
map[key] 但是当key如果不存在的时候,我们会得到该value值类型的默认值,比如string类型得到空字符串,int类型得到0。但是程序不会报错。value, ok := map[key]
len(map) // 可以得到map的长度
1.2.5 map是引用类型的
map是引用类型。当将映射分配给一个新变量时,它们都指向相同的内部数据结构。因此,一个的变化会反映另一个。
map不能使用==操作符进行比较。==只能用来检查map是否为空。否则会报错:invalid operation: map1 == map2 (map can only be comparedto nil)
Day09 string
1.1 什么是string
Go中的字符串是一个字节的切片。可以通过将其内容封装在“”中来创建字符串。Go中的字符串是Unicode兼容的,并且是UTF-8编码的。
1 | 字符串是一些字节的集合。 |
1.2 string的使用
1 | package main |
运行结果:
72 101 108 108 111 32 87 111 114 108 100
H e l l o W o r l d
Day10 函数
1.2 函数的声明
go语言至少有一个main函数,是程序的入口,支持匿名函数和闭包。
语法格式:
1 | func funcName(parametername type1, parametername type2) (output1 type1, output2 type2) { |
- func:函数由 func 开始声明
- funcName:函数名称,函数名和参数列表一起构成了函数签名。
- parametername type:参数列表,参数就像一个占位符,当函数被调用时,你可以将值传递给参数,这个值被称为实际参数。参数列表指定的是参数类型、顺序、及参数个数。参数是可选的,也就是说函数也可以不包含参数。
- output1 type1, output2 type2:返回类型,函数返回一列值。return_types 是该列值的数据类型。有些功能不需要返回值,这种情况下 return_types 不是必须的。
- 上面返回值声明了两个变量output1和output2,可以在函数内直接使用;如果你不想声明也可以,直接就两个类型。
- 如果只有一个返回值且不声明返回值变量,那么你可以省略包括返回值的括号(即一个返回值可以不声明返回类型)
- 函数体:函数定义的代码集合。
1 | 1.必须先定义,再调用,如果不定义:undefined: getSum |
1.3 函数的使用
示例代码:
1 | package main |
运行结果:
1 | 最大值是 : 200 |
二、函数的参数
2.1 参数的使用
形式参数:定义函数时,用于接收外部传入的数据,叫做形式参数,简称形参。
实际参数:调用函数时,传给形参的实际的数据,叫做实际参数,简称实参。
函数调用:
1 | A:函数名称必须匹配 |
2.2 可变参
Go函数支持变参。接受变参的函数是有着不定数量的参数的。为了做到这点,首先需要定义函数使其接受变参:
1 | func myfunc(arg ...int) {} |
arg ...int告诉Go这个函数接受不定数量的参数。注意,这些参数的类型全部是int。在函数体中,变量arg是一个int的slice:
1 | for _, n := range arg { |
1 | 1.当使用可变参数时,参数可以传入具体的数字,也可以传入使用...解构的slice对象; |
2.3 参数传递
go语言函数的参数也是存在值传递和引用传递>> go只有值传递
函数运用场景
值传递
1 | package main |
引用传递
这就牵扯到了所谓的指针。我们知道,变量在内存中是存放于一定地址上的,修改变量实际是修改变量地址处的内存。只有add1函数知道x变量所在的地址,才能修改x变量的值。所以我们需要将x所在地址&x传入函数,并将函数的参数的类型由int改为*int,即改为指针类型,才能在函数中修改x变量的值。此时参数仍然是按copy传递的,只是copy的是一个指针。请看下面的例子
1 | package main |
- 传指针使得多个函数能操作同一个对象。
- 传指针比较轻量级 (8bytes),只是传内存地址,我们可以用指针传递体积大的结构体。如果用参数值传递的话, 在每次copy上面就会花费相对较多的系统开销(内存和时间)。所以当你要传递大的结构体的时候,用指针是一个明智的选择。
- Go语言中slice,map这三种类型的实现机制类似指针,所以可以直接传递,而不用取地址后传递指针。(注:若函数需改变slice的长度,则仍需要取地址传递指针)???// todo
1 | 数据类型: |
三、函数的返回值
3.1 什么是函数的返回值
一个函数被调用后,返回给调用处的执行结果,叫做函数的返回值。调用处需要使用变量接收该结果,也可以忽略该值。
1 | return语句: |
3.2 一个函数可以返回多个值
一个函数可以没有返回值,也可以有一个返回值,也可以有返回多个值。
1 | package main |
1 | func SumAndProduct(A, B int) (add int, Multiplied int) { |
3.3 空白标识符
_是Go中的空白标识符,用于忽略返回值
作用域:变量可以使用的范围。
定义全局变量时,不能使用简短定义的写法
函数也是Go语言中的一种数据类型,可以作为另一个函数的参数,也可以作为另一个函数的返回值。
六、defer函数
6.2 延迟函数
你可以在函数中添加多个defer语句。当函数执行到最后时,这些defer语句会按照逆序执行,最后该函数返回。特别是当你在进行一些打开资源的操作时,遇到错误需要提前返回,在返回前你需要关闭相应的资源,不然很容易造成资源泄露等问题
- 如果有很多调用defer,那么defer是采用
后进先出模式 - 在离开所在的方法时,执行(报错的时候也会执行)
示例代码:
1 | package main |
运行结果:
1 | 1 |
示例代码:
1 | package main |
运行结果:
1 | Started finding largest |
6.3 延迟方法
延迟并不仅仅局限于函数。延迟一个方法调用也是完全合法的。让我们编写一个小程序来测试这个。
示例代码:
1 | package main |
运行结果:
1 | Welcome John Smith |
6.4 延迟参数
延迟函数的参数在执行延迟语句时被执行,而不是在执行实际的函数调用时执行。
让我们通过一个例子来理解这个问题。
示例代码:
1 | package main |
运行结果:
1 | value of a before deferred function call 10 |
以下例子证明,是将该defer函数所调用的值已经固定传过去了,如果是引用类型,则引用类型所指向的函数对象是可能变的。
1 | func main() { //外围函数 |
6.5 堆栈的推迟
当一个函数有多个延迟调用时,它们被添加到一个堆栈中,并在Last In First Out(LIFO)后进先出的顺序中执行。
我们将编写一个小程序,它使用一堆defers打印一个字符串。示例代码:
1 | package main |
运行结果:
1 | Orignal String: Naveen |
6.6 defer注意点
1 | defer函数: |
type:
数组类型是带着数据长度的:
1 | a := 10 |
匿名函数
匿名函数
函数当然还可以作为返回值,但是在Go语言中函数内部不能再像之前那样定义函数了,只能定义匿名函数。匿名函数就是没有函数名的函数,匿名函数的定义格式如下:
1 | func(参数)(返回值){ |
匿名函数因为没有函数名,所以没办法像普通函数那样调用,所以匿名函数需要保存到某个变量或者作为立即执行函数:
1 | func main() { |
匿名函数多用于实现回调函数和闭包。
闭包
闭包指的是一个函数和与其相关的引用环境组合而成的实体。简单来说,闭包=函数+引用环境。 首先我们来看一个例子:
1 | func adder() func(int) int { |
变量f是一个函数并且它引用了其外部作用域中的x变量,此时f就是一个闭包。 在f的生命周期内,变量x也一直有效。 闭包进阶示例1:
1 | func adder2(x int) func(int) int { |
闭包进阶示例2:
1 | func makeSuffixFunc(suffix string) func(string) string { |
闭包进阶示例3:
1 | func calc(base int) (func(int) int, func(int) int) { |
闭包其实并不复杂,只要牢记闭包=函数+引用环境。
内置函数介绍
| 内置函数 | 介绍 |
|---|---|
| close | 主要用来关闭channel |
| len | 用来求长度,比如string、array、slice、map、channel |
| new | 用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针 |
| make | 用来分配内存,主要用来分配引用类型,比如chan、map、slice |
| append | 用来追加元素到数组、slice中 |
| panic和recover | 用来做错误处理 |
day11 包管理
函数是代码复用的一种方案。包也是代码复用的一种方案。 Go 语言为我们提供了很多内置包,如 fmt 、strconv 、strings 、sort 、errors 、time 、encoding/json 、os 、io 等。
Golang 中的包可以分为三种 :1、系统内置包 2、自定义包 3、第三方包。
系统内置包 : Golang 语言给我们提供的内置包 ,引入后可以直接使用 ,如 fmt 、strconv 、strings 、sort 、errors 、time 、encoding/json 、os 、io 等。
自定义包 :开发者自己写的包
第三方包 :属于自定义包的一种 ,需要下载安装到本地后才可以使用 。
Go语言中包的使用
Go语言使用包(package)这种语法元素来组织源码,所有语法可见性均定义在package这个级别。
1、 main包
Go 语言的入口 main() 函数所在的包(package)叫 main,main 包想要引用别的代码,需要import导入!
2、 package
src 目录是以代码包的形式组织并保存 Go 源码文件的。每个代码包都和 src 目录下的文件夹一一对应。每个子目录都是一个代码包。
代码包包名和文件目录名,不要求一致。比如文件目录叫 hello,但是代码包包名可以声明为 “main”,但是同一个目录下的源码文件第一行声明的所属包,必须一致!
同一个文件夹下的文件的第一行所申明的所属包,必须一致。不包括子文件夹
同一个目录下的所有.go文件的第一行添加 包定义,以标记该文件归属的包,演示语法:
1 | package 包名 |
包需要满足:
- 一个目录下的同级文件归属一个包。也就是说,在同一个包下面的所有文件的package名,都是一样的。
- 在同一个包下面的文件
package名都建议设为是该目录名,但也可以不是。也就是说,包名可以与其目录不同名。 - 包名为 main 的包为应用程序的入口包,其他包不能使用。
在同一个包下面的文件属于同一个工程文件,不用
import包,可以直接使用
包可以嵌套定义,对应的就是嵌套目录,但包名应该与所在的目录一致,例如:
1 | // 文件:qf/ruby/tool.go中 |
包中,通过标识符首字母是否大写,来确定是否可以被导出。首字母大写才可以被导出,视为 public 公共的资源。
3、 import
要引用其他包,可以使用 import 关键字,可以单个导入或者批量导入,语法演示:
A:通常导入
1 | // 单个导入 |
B:点操作
我们有时候会看到如下的方式导入包
1 | import( |
这个点操作的含义就是这个包导入之后在你调用这个包的函数时,你可以省略前缀的包名,也就是前面你调
用的 fmt.Println("hello world")可以省略的写成 Println("hello world")
C:起别名
别名操作顾名思义我们可以把包命名成另一个我们用起来容易记忆的名字。导入时,可以为包定义别名,语法演示:
1 | import ( |
D:_操作
如果仅仅需要导入包时执行初始化操作,并不需要使用包内的其他函数,常量等资源。则可以在导入包时,匿名导入。
这个操作经常是让很多人费解的一个操作符,请看下面这个import:
1 | import ( |
_操作其实是引入该包,而不直接使用包里面的函数,而是调用了该包里面的init函数。也就是说,使用下划线作为包的别名,会仅仅执行init()。
导入的包的路径名,可以是相对路径也可以是绝对路径,推荐使用绝对路径(起始于工程根目录)。
4、GOPATH环境变量
import导入时,会从GO的安装目录(也就是GOROOT环境变量设置的目录)和GOPATH环境变量设置的目录中,检索 src/package 来导入包。如果不存在,则导入失败。
GOROOT,就是GO内置的包所在的位置。
GOPATH,就是我们自己定义的包的位置。
通常我们在开发Go项目时,调试或者编译构建时,需要设置GOPATH指向我们的项目目录,目录中的src目录中的包就可以被导入了。
5、init() 包初始化
下面我们详细的来介绍一下这两个函数:init()、main() 是 go 语言中的保留函数。我们可以在源码中定义 init() 函数。此函数会在包被导入时执行,例如如果是在 main 中导入包,包中存在 init(),那么 init() 中的代码会在 main() 函数执行前执行,用于初始化包所需要的特定资料。
init()、main() 这两个函数区别如下:
相同点:
两个函数在定义时不能有任何的参数和返回值。
该函数只能由 go 程序自动调用,不可以被引用。
不同点:
init 可以应用于任意包中,且可以重复定义多个。# init没有方法重载的概念
main 函数只能用于 main 包中,且只能定义一个。
两个函数的执行顺序:
在 main 包中的 go 文件默认总是会被执行。
对同一个 go 文件的 init( ) 调用顺序是从上到下的。
对同一个 package 中的不同文件,将文件名按字符串进行“从小到大”排序,之后顺序调用各文件中的init()函数。
对于不同的 package,如果不相互依赖的话,按照 main 包中 import 的顺序调用其包中的 init() 函数。
Day12 指针
go中的指针只有&和*
go中的函数传参都是值拷贝。
1.1 指针的概念
指针是存储另一个变量的内存地址的变量。变量是一种使用方便的占位符,用于引用计算机内存地址。
一个指针变量可以指向任何一个值的内存地址它指向那个值的内存地址。
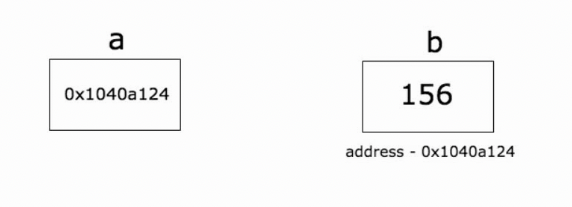
在上面的图中,变量b的值为156,存储在内存地址0x1040a124。变量a持有b的地址,现在a被认为指向b。
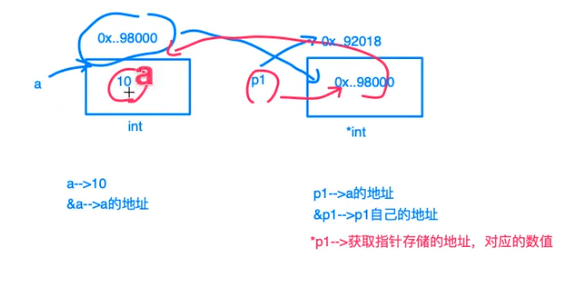
1.2 获取变量的地址
Go 语言的取地址符是 &,放到一个变量前使用就会返回相应变量的内存地址。
1.3 声明指针
声明指针,*T是指针变量的类型,它指向T类型的值。
1 | var var_name *var-type |
var-type 为指针类型,var_name 为指针变量名,* 号用于指定变量是作为一个指针。
1 | var ip *int /* 指向整型*/ |
1 | package main |
- 首先定义了一个整型变量
num,其初始值为50。 - 然后
ptr是指向num的指针,即*ptr就可以访问到num的值。 ptrToPtr是指向ptr的指针,也就是二级指针,通过**ptrToPtr能获取到num的值。ptrToPtrToPtr是指向ptrToPtr的指针,属于三级指针,利用***ptrToPtrToPtr同样可以操作num的值。- 最后
ptrToPtrToPtrToPtr是四层指针,通过****ptrToPtrToPtrToPtr可以对最底层的num变量进行赋值操作,将其修改为100,最后打印num时,输出的结果就是100了。
1.4 空指针
Go 空指针
当一个指针被定义后没有分配到任何变量时,它的值为 nil。
nil 指针也称为空指针。
nil在概念上和其它语言的null、None、nil、NULL一样,都指代零值或空值。
一个指针变量通常缩写为 ptr。
空指针判断:
1 | if(ptr != nil) /* ptr 不是空指针 */ |
1.5 获取指针的值
获取一个指针意味着访问指针指向的变量的值。语法是:*a
1.7 使用指针传递函数的参数
不要将一个指向数组的指针传递给函数。使用切片。
假设我们想对函数内的数组进行一些修改,并且对调用者可以看到函数内的数组所做的更改。一种方法是将一个指向数组的指针传递给函数。
虽然将指针传递给一个数组作为函数的参数并对其进行修改,但这并不是实现这一目标的惯用方法。我们有切片。
Go不支持指针算法。
package main
func main() {
b := […]int{109, 110, 111}
p := &b
p++
}nvalid operation: p++ (non-numeric type *[3]int)
1.8 指针的指针
指针的指针
如果一个指针变量存放的又是另一个指针变量的地址,则称这个指针变量为指向指针的指针变量。
1 | var ptr **int; |
1 | package main |
结果
1 | 变量 a = 3000 |
指针作为函数参数
1 | package main |
结果
1 | 交换前 a 的值 : 100 |
Day13 结构体
1 | var p1 Person |
1.2 结构体的定义和初始化
1 | type struct_variable_type struct { |
一旦定义了结构体类型,它就能用于变量的声明
1 | variable_name := structure_variable_type {value1, value2...valuen} |
初始化结构体
1 |
|
1.5 结构体的匿名字段
结构体的匿名字段
可以用字段来创建结构,这些字段只包含一个没有字段名的类型。这些字段被称为匿名字段,实际就是字段的继承。若存在匿名字段中的字段与非匿名字段名字相同,则最外层的优先访问,就近原则。
匿名struct赋值时,如果使用field:value赋值的方式,匿名的struct也需要声明类型
1 |
|
1.6 结构体嵌套、提升字段
嵌套的结构体
一个结构体可能包含一个字段,而这个字段反过来就是一个结构体。这些结构被称为嵌套结构。
在结构体中属于匿名结构体的字段称为提升字段,因为它们可以被访问,就好像它们属于拥有匿名结构字段的结构一样。
1.8 导出结构体和字段
如果结构体类型以大写字母开头,那么它是一个导出类型,可以从其他包访问它。类似地,如果结构体的字段以大写开头,则可以从其他包访问它们。
示例代码:
1.在computer目录下,创建文件spec.go
1 | package computer |
2.创建main.go 文件
1 | package main |
1.9 结构体比较
结构体是值类型,如果每个字段具有可比性,则是可比较的。如果它们对应的字段相等,则认为两个结构体变量是相等的。
示例代码:
1 | package main |
运行结果
1 | name1 and name2 are equal |
如果结构变量包含的字段是不可比较的,那么结构变量是不可比较的
示例代码:
1 | package main |
make、new操作
make用于内建类型(map、slice 和channel)的内存分配。new用于各种类型的内存分配
内建函数new本质上说跟其它语言中的同名函数功能一样:new(T)分配了零值填充的T类型的内存空间,并且返回其地址,即一个*T类型的值。用Go的术语说,它返回了一个指针,指向新分配的类型T的零值。有一点非常重要:new返回指针
内建函数make(T, args)与new(T)有着不同的功能,make只能创建slice、map和channel,并且返回一个有初始值(非零)的T类型,而不是*T。本质来讲,导致这三个类型有所不同的原因是指向数据结构的引用在使用前必须被初始化。例如,一个slice,是一个包含指向数据(内部array)的指针、长度和容量的三项描述符;在这些项目被初始化之前,slice为nil。对于slice、map和channel来说,make初始化了内部的数据结构,填充适当的值。
make返回初始化后的(非零)值。
Day14-1 方法
1.1 什么是方法
方法类似于java中的对象的方法,有一个对象的概念。
函数类似于java中工具类的概念,没有归属对象。
Go 语言中同时有函数和方法。一个方法就是一个包含了接受者的函数,接受者可以是命名类型或者结构体类型的一个值或者是一个指针。所有给定类型的方法属于该类型的方法集。
命名类型是什么?结构体类型是什么?
方法只是一个函数,它带有一个特殊的接收器类型,它是在func关键字和方法名之间编写的。接收器可以是struct类型或非struct类型。接收方可以在方法内部访问。
方法能给用户自定义的类型添加新的行为。它和函数的区别在于方法有一个接收者,给一个函数添加一个接收者,那么它就变成了方法。接收者可以是值接收者,也可以是指针接收者。
在调用方法的时候,值类型既可以调用值接收者的方法,也可以调用指针接收者的方法;指针类型既可以调用指针接收者的方法,也可以调用值接收者的方法。
也就是说,不管方法的接收者是什么类型,该类型的值和指针都可以调用,不必严格符合接收者的类型。
1.4 变量作用域
Go 语言中变量可以在三个地方声明:
- 函数内定义的变量称为局部变量
- 函数外定义的变量称为全局变量
- 函数定义中的变量称为形式参数
局部变量
在函数体内声明的变量称之为局部变量,它们的作用域只在函数体内,参数和返回值变量也是局部变量。
全局变量
在函数体外声明的变量称之为全局变量,首字母大写全局变量可以在整个包甚至外部包(被导出后)使用。
形式参数
形式参数会作为函数的局部变量来使用
指针作为接收者
若不是以指针作为接收者,实际只是获取了一个copy,而不能真正改变接收者的中的数据。
1.5 method继承-重写
method是可以继承的,如果匿名字段实现了一个method,那么包含这个匿名字段的struct也能直接调用该method,也可以通过父类对象去调用。
- 方法是可以继承和重写的
- 存在继承关系时,按照就近原则,进行调用
1 | OOP中的继承性: |
1 |
|
Day14-2 接口
1.1 什么是接口?
在Go中,接口是一组方法签名。当类型为接口中的所有方法提供定义时,它被称为实现接口。Go语言中,接口和类型的实现关系,是非侵入式。其他语言中是显示的定义实现关系:class Mouse implements USB{}。
1 | 1.当需要接口类型的对象时,可以使用任意实现类对象代替 |
接口定义了一组方法,如果某个对象实现了某个接口的所有方法,则此对象就实现了该接口。
接口是一种由程序员来定义的类型,一个接口类型就是一组方法的集合,它规定了需要实现的所有方法。
1.2 接口的定义语法
interface可以被任意的对象实现
一个对象可以实现任意多个interface
任意的类型都实现了空interface(我们这样定义:interface{}),也就是包含0个method的interface
接口类型名:Go语言的接口在命名时,一般会在单词后面添加
er,如有写操作的接口叫Writer,有关闭操作的接口叫closer等。接口名最好要能突出该接口的类型含义。方法名:当方法名首字母是大写且这个接口类型名首字母也是大写时,这个方法可以被接口所在的包(package)之外的代码访问。
接口类型变量
一个接口类型的变量能够存储所有实现了该接口的类型变量。
1 | // 值接收者实现的接口,可以将具体的struct类型和对应struct对应的类型指针赋值给该接口类型的变量; |
一个接口的所有方法,不一定需要由一个类型完全实现,接口的方法可以通过在类型中嵌入其他类型或者结构体来实现。
1 | package main |
1.3 interface值
1 | package main |
运行结果:
1 | This is Mike, a Student: |
那么interface里面到底能存什么值呢?如果我们定义了一个interface的变量,那么这个变量里面可以存实现这个interface的任意类型的对象。例如上面例子中,我们定义了一个Men interface类型的变量m,那么m里面可以存Human、Student或者Employee值
当然,使用指针的方式,也是可以的
但是,接口对象不能调用实现对象的属性
interface函数参数
interface的变量可以持有任意实现该interface类型的对象,这给我们编写函数(包括method)提供了一些额外的思考,我们是不是可以通过定义interface参数,让函数接受各种类型的参数
嵌入interface
1 | package main |
示例代码:
1 | package test |
1 | package main |
Controller实现了所有的Something接口方法,当结构体T中调用Controller结构体的时候,T就相当于Java中的继承,T继承了Controller,因此,T可以不用重写所有的Something接口中的方法,因为父构造器已经实现了接口。
如果Controller没有实现Something接口方法,则T要调用Something中方法,就要实现其所有方法。
如果 something = new(test.Controller)则调用的是Controller中的Get方法。
T可以使用Controller结构体中定义的变量
1.4 接口的类型
接口与鸭子类型:
Duck Typing,鸭子类型,是动态编程语言的一种对象推断策略,它更关注对象能如何被使用,而不是对象的类型本身。Go 语言作为一门静态语言,它通过通过接口的方式完美支持鸭子类型。
而在静态语言如 Java, C++ 中,必须要显示地声明实现了某个接口,之后,才能用在任何需要这个接口的地方。如果你在程序中调用某个数,却传入了一个根本就没有实现另一个的类型,那在编译阶段就不会通过。这也是静态语言比动态语言更安全的原因。
动态语言和静态语言的差别在此就有所体现。静态语言在编译期间就能发现类型不匹配的错误,不像动态语言,必须要运行到那一行代码才会报错。当然,静态语言要求程序员在编码阶段就要按照规定来编写程序,为每个变量规定数据类型,这在某种程度上,加大了工作量,也加长了代码量。动态语言则没有这些要求,可以让人更专注在业务上,代码也更短,写起来更快,这一点,写 python 的同学比较清楚。
Go 语言作为一门现代静态语言,是有后发优势的。它引入了动态语言的便利,同时又会进行静态语言的类型检查,写起来是非常 Happy 的。Go 采用了折中的做法:不要求类型显示地声明实现了某个接口,只要实现了相关的方法即可,编译器就能检测到。
Go语言的多态性:
Go中的多态性是在接口的帮助下实现的。正如我们已经讨论过的,接口可以在Go中隐式地实现。如果类型为接口中声明的所有方法提供了定义,则实现一个接口。让我们看看在接口的帮助下如何实现多态。
任何定义接口所有方法的类型都被称为隐式地实现该接口。
类型接口的变量可以保存实现接口的任何值。接口的这个属性用于实现Go中的多态性。
1.5 接口断言
前面说过,因为空接口 interface{}没有定义任何函数,因此 Go 中所有类型都实现了空接口。当一个函数的形参是interface{},那么在函数中,需要对形参进行断言,从而得到它的真实类型。
语法格式:
1 | // 安全类型断言 |
示例代码:
1 | package main |
断言其实还有另一种形式,就是用在利用 switch语句判断接口的类型。每一个case会被顺序地考虑。当命中一个case 时,就会执行 case 中的语句,因此 case 语句的顺序是很重要的,因为很有可能会有多个 case匹配的情况。
示例代码:
1 | switch ins:=s.(type) { |
总结
接口对象不能调用接口实现对象的属性
Day14-3 OOP编程
go并不是一个纯面向对象的编程语言。在go中的面向对象,结构体替换了类。
Go并没有提供类class,但是它提供了结构体struct,方法method,可以在结构体上添加。提供了捆绑数据和方法的行为,这些数据和方法与类类似。
1.1 定义结构体和方法
在employee.go文件中保存以下代码:
1 | package main |
创建文件并命名为main.go,并保存以下内容
1 | package main |
运行结果:
1 | Sam Adolf has 10 leaves remaining |
1.2 New()函数替代了构造函数
我们上面写的程序看起来不错,但是里面有一个微妙的问题。让我们看看当我们用0值定义employee struct时会发生什么。更改main的内容。转到下面的代码,
1 | package main |
运行结果:
1 | has 0 leaves remaining |
通过运行结果可以知道,使用Employee的零值创建的变量是不可用的。它没有有效的名、姓,也没有有效的保留细节。在其他的OOP语言中,比如java,这个问题可以通过使用构造函数来解决。使用参数化构造函数可以创建一个有效的对象。
go不支持构造函数。如果某个类型的零值不可用,则程序员的任务是不导出该类型以防止其他包的访问,并提供一个名为NewT(parameters)的函数,该函数初始化类型T和所需的值。在go中,它是一个命名一个函数的约定,它创建了一个T类型的值给NewT(parameters)。这就像一个构造函数。如果包只定义了一个类型,那么它的一个约定就是将这个函数命名为New(parameters)而不是NewT(parameters)。
更改employee.go的代码:
首先修改employee结构体为非导出,并创建一个函数New(),它将创建一个新Employee。代码如下:
1 | package main |
我们在这里做了一些重要的改变。我们已经将Employee struct的起始字母e设置为小写,即我们已经将类型Employee struct更改为type employee struct。通过这样做,我们成功地导出了employee结构并阻止了其他包的访问。将未导出的结构的所有字段都导出为未导出的方法是很好的做法,除非有特定的需要导出它们。由于我们不需要在包之外的任何地方使用employee struct的字段,所以我们也没有导出所有字段。
由于employee是未导出的,所以不可能从其他包中创建类型employee的值。因此,我们提供了一个输出的新函数。将所需的参数作为输入并返回新创建的employee。
这个程序还需要做一些修改,让它能够工作,但是让我们运行这个程序来了解到目前为止变化的效果。如果这个程序运行,它将会失败,有以下编译错误,
1 | go/src/constructor/main.go:6: undefined: employee.Employee |
这是因为我们有未导出的Employee,因此编译器抛出错误,该类型在main中没有定义。完美的。正是我们想要的。现在没有其他的包能够创建一个零值的员工。我们成功地防止了一个无法使用的员工结构价值被创建。现在创建员工的唯一方法是使用新功能。
修改main.go代码
1 | package main |
运行结果:
1 | Sam Adolf has 10 leaves remaining |
因此,我们可以明白,虽然Go不支持类,但是结构体可以有效地使用,在使用构造函数的位置,使用New(parameters)的方法即可。
1.3组成(Composition )替代了继承(Inheritance)
Go不支持继承,但它支持组合。组合的一般定义是“放在一起”。
1.3.1 通过嵌入结构体实现组成
可以通过将一个struct类型嵌入到另一个结构中实现。
示例代码:
1 | package main |
运行结果:
1 | Title: Inheritance in Go |
嵌入结构体的切片
在以上程序的main函数下增加以下代码,并运行
1 | type website struct { |
运行报错:
1 | main.go:31:9: syntax error: unexpected [, expecting field name or embedded type |
这个错误指向structs []post的嵌入部分。原因是不可能匿名嵌入一片。需要一个字段名。我们来修正这个错误,让编译器通过。
1 | type website struct { |
现在让我们修改的main函数,为我们的新的website创建几个posts。修改完完整代码如下:
1 | package main |
Day14-4 type
type是go语法里的重要而且常用的关键字。搞清楚type的使用,就容易理解go语言中的核心概念struct、interface、函数等的使用。
一、类型定义
1.使用type 可以定义结构体类型
2.使用type 可以定义接口类型
3.使用type,还可以定义新类型:原类型和新类型不能相互赋值
语法:
1 | type 类型名 Type |
示例代码:
1 | package main |
4.定义函数的类型
Go语言支持函数式编程,可以使用高阶编程语法。一个函数可以作为另一个函数的参数,也可以作为另一个函数的返回值,那么在定义这个高阶函数的时候,如果函数的类型比较复杂,我们可以使用type来定义这个函数的类型:
定义函数类型时,感觉好像只是给新定义的函数起了个别名,只要方法签名一样,就可以使用定义的别名来替代写这个复杂的函数签名,他们还是一个东西,不像type定义新类型时,无法相互赋值。
1 | package main |
二、类型别名
类型别名的写法为:
1 | type 别名 = Type |
类型别名规定:TypeAlias 只是 Type 的别名,本质上 TypeAlias 与 Type 是同一个类型。
类型别名是 Go 1.9 版本添加的新功能。主要用于代码升级、迁移中类型的兼容性问题。
在 Go 1.9 版本之前的内建类型定义的代码是这样写的:
1 | type byte uint8 |
而在 Go 1.9 版本之后变为:
1 | type byte = uint8 |
这个修改就是配合类型别名而进行的修改。
三、非本地类型不能定义方法
能够随意地为各种类型起名字,是否意味着可以在自己包里为这些类型任意添加方法?
1 | package main |
以上代码报错。报错信息:cannot define new methods on non-local type time.Duration
编译器提示:不能在一个非本地的类型 time.Duration 上定义新方法。非本地方法指的就是使用 time.Duration 的代码所在的包,也就是 main 包。因为 time.Duration 是在 time 包中定义的,在 main 包中使用。time.Duration 包与 main 包不在同一个包中,因此不能为不在一个包中的类型定义方法。
解决这个问题有下面两种方法:
- 将类型别名改为类型定义: type MyDuration time.Duration,也就是将 MyDuration 从别名改为类型。
- 将 MyDuration 的别名定义放在 time 包中。
四、在结构体成员嵌入时使用别名
当类型别名作为结构体嵌入的成员时会发生什么情况?
1 | package main |
在通过s直接访问name的时候,或者s直接调用Show()方法,因为两个类型都有 name字段和Show() 方法,会发生歧义,证明People 的本质确实是Person 类型。
部分内容引自:http://c.biancheng.net/view/25.html
Day15 错误处理
Go语言没有提供像 Java、C#语言中的 try...catch异常处理方式,而是通过函数返回值逐层往上抛,Go中的错误也是一种类型。错误用内置的 error 类型表示。
错误/异常的对比
错误是意料之中的问题,比如打开一个文件时失败 。
而异常是意料之外问题。比如引用了空指针。可见,错误是业务过程的一部分,而异常不是
由于 error 是一个接口类型,默认零值为nil。所以我们通常将调用函数返回的错误与nil进行比较,以此来判断函数是否返回错误。
1.2 演示错误
尝试打开一个不存在的文件。
示例代码:
1 | package main |
在os包中有打开文件的功能函数:
func Open(name string) (file*File, err error)
如果文件已经成功打开,那么Open函数将返回文件处理。如果在打开文件时出现错误,将返回一个非nil错误。
处理错误的惯用方法是将返回的错误与nil进行比较。nil值表示没有发生错误,而非nil值表示出现错误。在我们的例子中,我们检查错误是否为nil。如果它不是nil,我们只需打印错误并从主函数返回。
运行结果:
1 | open /test.txt: No such file or directory |
我们得到一个错误,说明该文件不存在。
1.3 错误类型表示
Go 语言通过内置的错误接口提供了非常简单的错误处理机制。
让我们再深入一点,看看如何定义错误类型的构建。错误是一个带有以下定义的接口类型,
1 | // todo 这里的error为什么不使用大写Error,将这个类型导出? |
它包含一个带有Error()字符串的方法。任何实现这个接口的类型都可以作为一个错误使用。这个方法提供了对错误的描述。
当打印错误时,fmt.Println函数在内部调用Error() 方法来获取错误的描述。这就是错误描述是如何在一行中打印出来的。
从错误中提取更多信息的不同方法
1.断言底层结构类型并从结构字段获取更多信息
如果仔细阅读打开函数的文档,可以看到它返回的是PathError类型的错误。PathError是一个struct类型,它在标准库中的实现如下,
1 | type PathError struct { |
从上面的代码中,您可以理解PathError通过声明 Error()string方法实现了错误接口。该方法连接操作、路径和实际错误并返回它。这样我们就得到了错误信息,
1 | open /test.txt: No such file or directory |
PathError结构的路径字段包含导致错误的文件的路径。让我们修改上面写的程序,并打印出路径。
修改代码:
1 | package main |
在上面的程序中,我们使用类型断言获得错误接口的基本值。然后我们用错误来打印路径.这个程序输出,
1 | File at path /test.txt failed to open |
- 断言底层结构类型,并使用方法获取更多信息
获得更多信息的第二种方法是断言底层类型,并通过调用struct类型的方法获取更多信息。
示例代码:
1 | type DNSError struct { |
从上面的代码中可以看到,DNSError struct有两个方法Timeout() bool和Temporary() bool,它们返回一个布尔值,表示错误是由于超时还是临时的。
让我们编写一个断言DNSError类型的程序,并调用这些方法来确定错误是临时的还是超时的。
1 | package main |
在上面的程序中,我们正在尝试获取一个无效域名的ip地址,这是一个无效的域名。golangbot123.com。我们通过声明它来输入*net.DNSError来获得错误的潜在价值。
在我们的例子中,错误既不是暂时的,也不是由于超时,因此程序会打印出来,
1 | generic error: lookup golangbot123.com: no such host |
如果错误是临时的或超时的,那么相应的If语句就会执行,我们可以适当地处理它。
3.直接比较
获得更多关于错误的详细信息的第三种方法是直接与类型错误的变量进行比较。让我们通过一个例子来理解这个问题。
filepath包的Glob函数用于返回与模式匹配的所有文件的名称。当模式出现错误时,该函数将返回一个错误ErrBadPattern。
在filepath包中定义了ErrBadPattern,如下所述:
1 | var ErrBadPattern = errors.New("syntax error in pattern") |
errors.New()用于创建新的错误。
当模式出现错误时,由Glob函数返回ErrBadPattern。
让我们写一个小程序来检查这个错误:
1 | package main |
运行结果:
1 | syntax error in pattern |
不要忽略错误
永远不要忽略一个错误。忽视错误会招致麻烦。让我重新编写一个示例,该示例列出了与模式匹配的所有文件的名称,而忽略了错误处理代码。
1 | package main |
我们从前面的例子中已经知道模式是无效的。我忽略了Glob函数返回的错误,方法是使用行号中的空白标识符。
1 | matched files [] |
由于我们忽略了这个错误,输出看起来好像没有文件匹配这个模式,但是实际上这个模式本身是畸形的。所以不要忽略错误。
1.4 自定义错误
创建自定义错误可以使用errors包下的New()函数,以及fmt包下的:Errorf()函数。
1 | //errors包: |
在使用New()函数创建自定义错误之前,让我们了解它是如何实现的。下面提供了错误包中的新功能的实现。
1 | // Package errors implements functions to manipulate errors. |
既然我们知道了New()函数是如何工作的,那么就让我们在自己的程序中使用它来创建一个自定义错误。
我们将创建一个简单的程序,计算一个圆的面积,如果半径为负,将返回一个错误。
1 | package main |
运行结果:
1 | Area calculation failed, radius is less than zero |
使用Errorf向错误添加更多信息
上面的程序运行得很好,但是如果我们打印出导致错误的实际半径,那就不好了。这就是fmt包的Errorf函数的用武之地。这个函数根据一个格式说明器格式化错误,并返回一个字符串作为值来满足错误。
使用Errorf函数,修改程序。
1 | package main |
运行结果:
1 | Area calculation failed, radius -20.00 is less than zero |
使用struct类型和字段提供关于错误的更多信息
还可以使用将错误接口实现为错误的struct类型。这给我们提供了更多的错误处理的灵活性。在我们的示例中,如果我们想要访问导致错误的半径,那么现在唯一的方法是解析错误描述区域计算失败,半径-20.00小于零。这不是一种正确的方法,因为如果描述发生了变化,我们的代码就会中断。
我们将使用在前面的教程中解释的标准库的策略,在“断言底层结构类型并从struct字段获取更多信息”,并使用struct字段来提供对导致错误的半径的访问。我们将创建一个实现错误接口的struct类型,并使用它的字段来提供关于错误的更多信息。
第一步是创建一个struct类型来表示错误。错误类型的命名约定是,名称应该以文本Error结束。让我们把struct类型命名为areaError
1 | type areaError struct { |
上面的struct类型有一个字段半径,它存储了为错误负责的半径的值,并且错误字段存储了实际的错误消息。
下一步,是实现error 接口
1 | func (e *areaError) Error() string { |
在上面的代码片段中,我们使用一个指针接收器区域错误来实现错误接口的Error() string方法。这个方法打印出半径和错误描述。
1 | package main |
程序输出:
1 | Radius -20.00 is less than zero |
使用结构类型的方法提供关于错误的更多信息
在本节中,我们将编写一个程序来计算矩形的面积。如果长度或宽度小于0,这个程序将输出一个错误。
第一步是创建一个结构来表示错误。
1 | type areaError struct { |
上面的错误结构类型包含一个错误描述字段,以及导致错误的长度和宽度。
现在我们有了错误类型,让我们实现错误接口,并在错误类型上添加一些方法来提供关于错误的更多信息。
1 | func (e *areaError) Error() string { |
在上面的代码片段中,我们返回 Error() string 方法的错误描述。当长度小于0时,lengthNegative() bool方法返回true;当宽度小于0时,widthNegative() bool方法返回true。这两种方法提供了更多关于误差的信息,在这种情况下,他们说面积计算是否失败,因为长度是负的,还是宽度为负的。因此,我们使用了struct错误类型的方法来提供更多关于错误的信息。
下一步是写出面积计算函数。
1 | func rectArea(length, width float64) (float64, error) { |
上面的rectArea函数检查长度或宽度是否小于0,如果它返回一个错误消息,则返回矩形的面积为nil。
主函数:
1 | func main() { |
运行结果:
1 | error: length -5.00 is less than zero |
不熟悉
当我们需要传入格式化的错误描述信息时,使用fmt.Errorf是个更好的选择。
1 | fmt.Errorf("查询数据库失败,err:%v", err) |
但是上面的方式会丢失原有的错误类型,只拿到错误描述的文本信息。
为了不丢失函数调用的错误链,使用fmt.Errorf时搭配使用特殊的格式化动词%w,可以实现基于已有的错误再包装得到一个新的错误。
1 | fmt.Errorf("查询数据库失败,err:%w", err) |
1 | func Unwrap(err error) error // 获得err包含下一层错误 |
1 | package main |
1.5 panic()和recover()
Golang中引入两个内置函数panic和recover来触发和终止异常处理流程,同时引入关键字defer来延迟执行defer后面的函数。
一直等到包含defer语句的函数执行完毕时,延迟函数(defer后的函数)才会被执行,而不管包含defer语句的函数是通过return的正常结束,还是由于panic导致的异常结束。你可以在一个函数中执行多条defer语句,它们的执行顺序与声明顺序相反。
当程序运行时,如果遇到引用空指针、下标越界或显式调用panic函数等情况,则先触发panic函数的执行,然后调用延迟函数。调用者继续传递panic,因此该过程一直在调用栈中重复发生:函数停止执行,调用延迟执行函数等。如果一路在延迟函数中没有recover函数的调用,则会到达该协程的起点,该协程结束,然后终止其他所有协程,包括主协程(类似于C语言中的主线程,该协程ID为1)。
panic:
1、内建函数
2、假如函数F中书写了panic语句,会终止其后要执行的代码,在panic所在函数F内如果存在要执行的defer函数列表,按照defer的逆序执行
3、返回函数F的调用者G,在G中,调用函数F语句之后的代码不会执行,假如函数G中存在要执行的defer函数列表,按照defer的逆序执行,这里的defer 有点类似 try-catch-finally 中的 finally
4、直到goroutine整个退出,并报告错误
recover:
1、内建函数
2、用来控制一个goroutine的panicking行为,捕获panic,从而影响应用的行为
3、一般的调用建议
a). 在defer函数中,通过recever来终止一个gojroutine的panicking过程,从而恢复正常代码的执行
b). 可以获取通过panic传递的error
简单来讲:go中可以抛出一个panic的异常,然后在defer中通过recover捕获这个异常,然后正常处理。
错误和异常从Golang机制上讲,就是error和panic的区别。很多其他语言也一样,比如C++/Java,没有error但有errno,没有panic但有throw。
Golang错误和异常是可以互相转换的:
- 错误转异常,比如程序逻辑上尝试请求某个URL,最多尝试三次,尝试三次的过程中请求失败是错误,尝试完第三次还不成功的话,失败就被提升为异常了。
- 异常转错误,比如panic触发的异常被recover恢复后,将返回值中error类型的变量进行赋值,以便上层函数继续走错误处理流程。
什么情况下用错误表达,什么情况下用异常表达,就得有一套规则,否则很容易出现一切皆错误或一切皆异常的情况。
以下给出异常处理的作用域(场景):
- 空指针引用
- 下标越界
- 除数为0
- 不应该出现的分支,比如default
- 输入不应该引起函数错误
其他场景我们使用错误处理,这使得我们的函数接口很精炼。对于异常,我们可以选择在一个合适的上游去recover,并打印堆栈信息,使得部署后的程序不会终止。
说明: Golang错误处理方式一直是很多人诟病的地方,有些人吐槽说一半的代码都是”if err != nil { / 打印 && 错误处理 / }”,严重影响正常的处理逻辑。当我们区分错误和异常,根据规则设计函数,就会大大提高可读性和可维护性。
1.6 错误处理的正确姿势
姿势一:失败的原因只有一个时,不使用error
我们看一个案例:
1 | func (self *AgentContext) CheckHostType(host_type string) error { |
我们可以看出,该函数失败的原因只有一个,所以返回值的类型应该为bool,而不是error,重构一下代码:
1 | func (self *AgentContext) IsValidHostType(hostType string) bool { |
说明:大多数情况,导致失败的原因不止一种,尤其是对I/O操作而言,用户需要了解更多的错误信息,这时的返回值类型不再是简单的bool,而是error。
姿势二:没有失败时,不使用error
error在Golang中是如此的流行,以至于很多人设计函数时不管三七二十一都使用error,即使没有一个失败原因。
我们看一下示例代码:
1 | func (self *CniParam) setTenantId() error { |
对于上面的函数设计,就会有下面的调用代码:
1 | err := self.setTenantId() |
根据我们的正确姿势,重构一下代码:
1 | func (self *CniParam) setTenantId() { |
于是调用代码变为:
1 | self.setTenantId() |
姿势三:error应放在返回值类型列表的最后
对于返回值类型error,用来传递错误信息,在Golang中通常放在最后一个。
1 | resp, err := http.Get(url) |
bool作为返回值类型时也一样。
1 | value, ok := cache.Lookup(key) |
姿势四:错误值统一定义,而不是跟着感觉走
很多人写代码时,到处return errors.New(value),而错误value在表达同一个含义时也可能形式不同,比如“记录不存在”的错误value可能为:
- “record is not existed.”
- “record is not exist!”
- “###record is not existed!!!”
- …
这使得相同的错误value撒在一大片代码里,当上层函数要对特定错误value进行统一处理时,需要漫游所有下层代码,以保证错误value统一,不幸的是有时会有漏网之鱼,而且这种方式严重阻碍了错误value的重构。
于是,我们可以参考C/C++的错误码定义文件,在Golang的每个包中增加一个错误对象定义文件,如下所示:
1 | var ERR_EOF = errors.New("EOF") |
姿势五:错误逐层传递时,层层都加日志
层层都加日志非常方便故障定位。
说明:至于通过测试来发现故障,而不是日志,目前很多团队还很难做到。如果你或你的团队能做到,那么请忽略这个姿势。
姿势六:错误处理使用defer
我们一般通过判断error的值来处理错误,如果当前操作失败,需要将本函数中已经create的资源destroy掉,示例代码如下:
1 | func deferDemo() error { |
当Golang的代码执行时,如果遇到defer的闭包调用,则压入堆栈。当函数返回时,会按照后进先出的顺序调用闭包。
对于闭包的参数是值传递,而对于外部变量却是引用传递,所以闭包中的外部变量err的值就变成外部函数返回时最新的err值。
根据这个结论,我们重构上面的示例代码:
1 | func deferDemo() error { |
姿势七:当尝试几次可以避免失败时,不要立即返回错误
如果错误的发生是偶然性的,或由不可预知的问题导致。一个明智的选择是重新尝试失败的操作,有时第二次或第三次尝试时会成功。在重试时,我们需要限制重试的时间间隔或重试的次数,防止无限制的重试。
两个案例:
- 我们平时上网时,尝试请求某个URL,有时第一次没有响应,当我们再次刷新时,就有了惊喜。
- 团队的一个QA曾经建议当Neutron的attach操作失败时,最好尝试三次,这在当时的环境下验证果然是有效的。
姿势八:当上层函数不关心错误时,建议不返回error
对于一些资源清理相关的函数(destroy/delete/clear),如果子函数出错,打印日志即可,而无需将错误进一步反馈到上层函数,因为一般情况下,上层函数是不关心执行结果的,或者即使关心也无能为力,于是我们建议将相关函数设计为不返回error。
姿势九:当发生错误时,不忽略有用的返回值
通常,当函数返回non-nil的error时,其他的返回值是未定义的(undefined),这些未定义的返回值应该被忽略。然而,有少部分函数在发生错误时,仍然会返回一些有用的返回值。比如,当读取文件发生错误时,Read函数会返回可以读取的字节数以及错误信息。对于这种情况,应该将读取到的字符串和错误信息一起打印出来。
说明:对函数的返回值要有清晰的说明,以便于其他人使用。
1.7 异常处理的正确姿势
姿势一:在程序开发阶段,坚持速错
速错,简单来讲就是“让它挂”,只有挂了你才会第一时间知道错误。在早期开发以及任何发布阶段之前,最简单的同时也可能是最好的方法是调用panic函数来中断程序的执行以强制发生错误,使得该错误不会被忽略,因而能够被尽快修复。
姿势二:在程序部署后,应恢复异常避免程序终止
在Golang中,某个Goroutine如果panic了,并且没有recover,那么整个Golang进程就会异常退出。所以,一旦Golang程序部署后,在任何情况下发生的异常都不应该导致程序异常退出,我们在上层函数中加一个延迟执行的recover调用来达到这个目的,并且是否进行recover需要根据环境变量或配置文件来定,默认需要recover。
这个姿势类似于C语言中的断言,但还是有区别:一般在Release版本中,断言被定义为空而失效,但需要有if校验存在进行异常保护,尽管契约式设计中不建议这样做。在Golang中,recover完全可以终止异常展开过程,省时省力。
我们在调用recover的延迟函数中以最合理的方式响应该异常:
- 打印堆栈的异常调用信息和关键的业务信息,以便这些问题保留可见;
- 将异常转换为错误,以便调用者让程序恢复到健康状态并继续安全运行。
我们看一个简单的例子:
1 | func funcA() error { |
我们期望test函数的输出是:
1 | err is foo |
实际上test函数的输出是:
1 | err is nil |
原因是panic异常处理机制不会自动将错误信息传递给error,所以要在funcA函数中进行显式的传递,代码如下所示:
1 | func funcA() (err error) { |
姿势三:对于不应该出现的分支,使用异常处理
当某些不应该发生的场景发生时,我们就应该调用panic函数来触发异常。比如,当程序到达了某条逻辑上不可能到达的路径:
1 | switch s := suit(drawCard()); s { |
姿势四:针对入参不应该有问题的函数,使用panic设计
入参不应该有问题一般指的是硬编码,我们先看这两个函数(Compile和MustCompile),其中MustCompile函数是对Compile函数的包装:
1 | func MustCompile(str string) *Regexp { |
所以,对于同时支持用户输入场景和硬编码场景的情况,一般支持硬编码场景的函数是对支持用户输入场景函数的包装。
对于只支持硬编码单一场景的情况,函数设计时直接使用panic,即返回值类型列表中不会有error,这使得函数的调用处理非常方便(没有了乏味的”if err != nil {/ 打印 && 错误处理 /}”代码块)。
本文部分内容引自https://www.jianshu.com/p/f30da01eea97
对应视频地址:
https://www.bilibili.com/video/av47467197
https://www.bilibili.com/video/av56018934/
源代码: